

最近一段时间,随着 OpenAI o1 模型的推出,关于大型语言模型是否拥有推理能力的讨论又多了起来。比如苹果在前段时间的一篇论文中指出,只要给模型一些干扰,最聪明的模型也会犯最简单的错误。这种现象被归结为「当前的 LLM 无法进行真正的逻辑推理;相反,它们试图复制在训练数据中观察到的推理步骤」。然而,事实真的是这样吗?谷歌 DeepMind 的一篇论文似乎得出了相反的结论。
最近,DeepMind 今年 2 月份的一篇论文在社交媒体上掀起了一些波澜。

关于该论文的早期报道。
这篇论文题为「Grandmaster-Level Chess Without Search」。文中介绍说,DeepMind 的研究者训练了一个参数量为 2.7 亿的 Transformer 模型,这个模型无需依赖复杂的搜索算法或启发式算法就能达到「特级大师( Grandmaster-Level )」的国际象棋水平,优于 AlphaZero 的策略和价值网络(不含 MCTS)以及 GPT-3.5-turbo-instruct 模型。
这一结果非常有趣,也很容易激发想象力,因为到目前为止,能达到这个级别的计算机国际象棋系统 —— 无论是否基于机器学习 —— 都使用了搜索组件。而 DeepMind 模型不依赖搜索似乎就能达到如此强大的下棋水平。
很多人将其解读为:这表明 Transformer 不是简单的「随机鹦鹉」,而是具有一定的推理和规划能力。就连该论文的作者也在「结论」部分写道:「我们的工作为快速增长的文献增添了新的内容,这些文献表明,复杂而精密的算法可以被蒸馏为前馈 transformer,这意味着一种范式的转变,即从将大型 transformer 视为单纯的统计模式识别器,转变为将其视为通用算法近似的强大技术。」
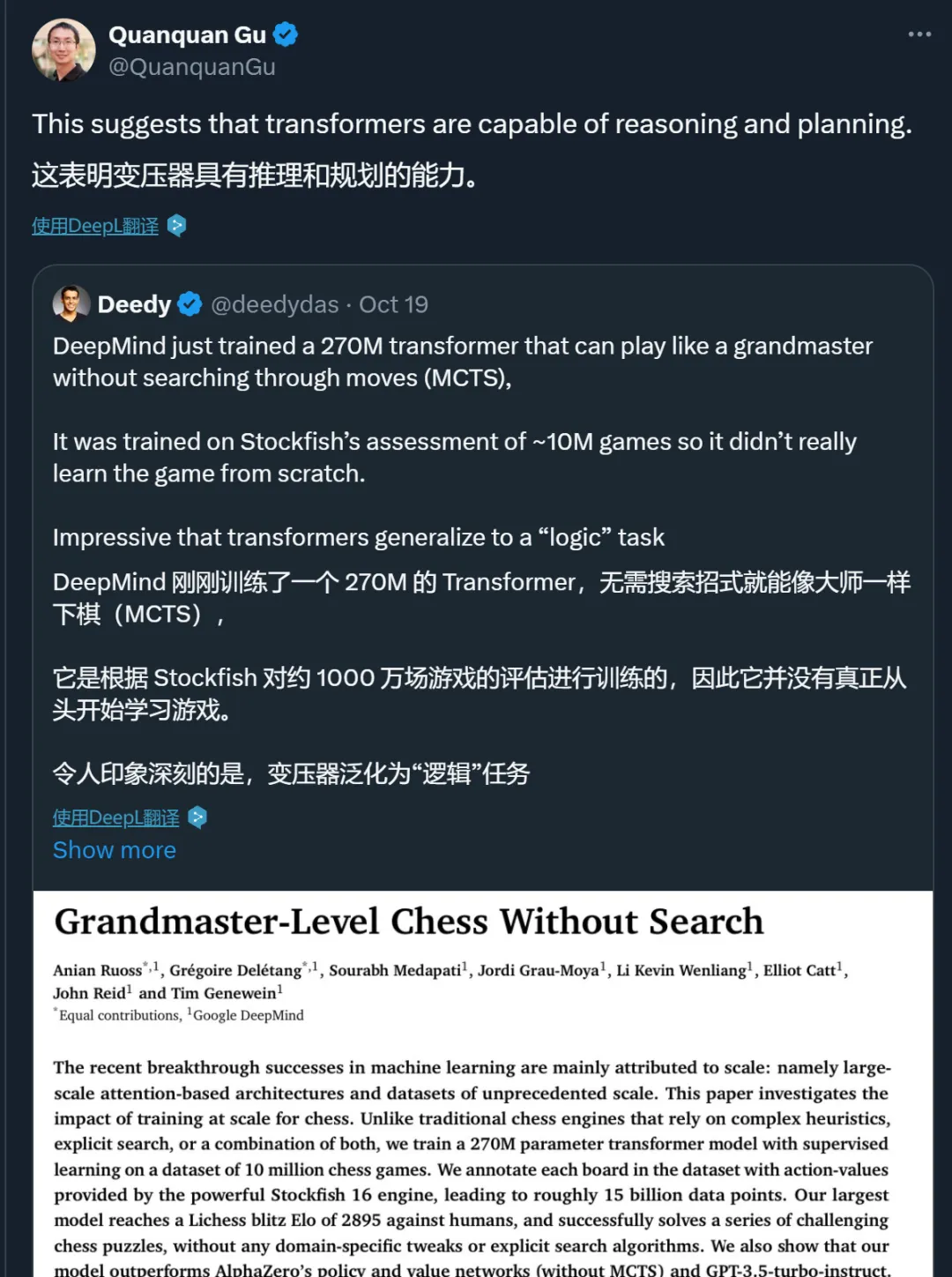
不过,这种解读也引来了一些争议。比如,Meta FAIR 研究科学家主任田渊栋指出,论文采用的评估方法 ——「blitz」可能存在一些局限。「blitz」字面意思是闪电战,在国际象棋中指超快棋。在这种棋赛中,对局每方仅有几分钟的时间思考,玩家往往依赖直觉而非深入的搜索和解决问题的能力。此外,模型与机器人对弈时的分数比与人类对弈时的分数要低。田渊栋认为这可能是因为人类在有限的时间内可能没有机器人那么擅长发现战术上的失误。所以,这种比赛可能并不足以用来测试模型是否拥有推理能力。
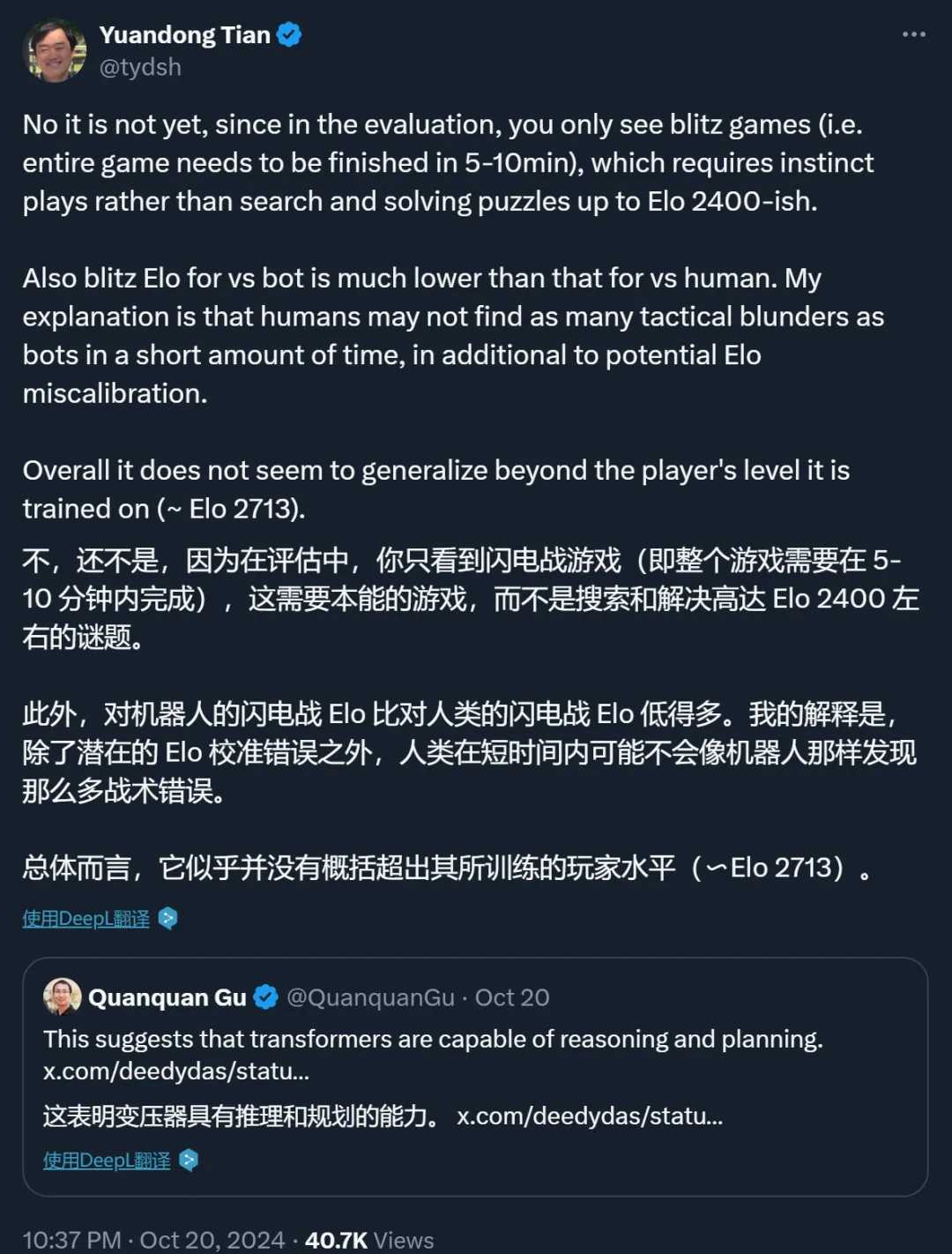
一向喜欢唱反调的纽约大学教授 Gary Marcus 这次也没有缺席,他也认为论文的结论被夸大了,模型的泛化能力存在严重问题。
其实,在今年 2 月份论文刚出来的时候,就有一些研究者写过关于该论文的质疑文章,有兴趣的读者可以点开阅读。

博客链接:https://arjunpanickssery.substack.com/p/skepticism-about-deepminds-grandmaster
博客链接:https://gist.github.com/yoavg/8b98bbd70eb187cf1852b3485b8cda4f#user-content-fnref-3-b6ec0872d32c5df9324eccad8269953b
论文概览
人工智能最具标志性的成功之一是 IBM 的深蓝(Deep Blue)在 1997 年击败了国际象棋冠军 Garry Kasparov。人们普遍认为,这证明了机器能够在需要复杂理性推理和战略规划的智力领域中超越人类 —— 而这些智力领域一直被认为只有人类才能涉足。
深蓝是一个专家系统,它结合了广泛的象棋知识和启发式规则以及强大的树搜索算法(alpha-beta 剪枝)。几乎所有当代且更强大的象棋引擎都遵循类似的模式,目前世界上最强大的(公开可用的)引擎是 Stockfish 16。
值得注意的例外是 DeepMind 的 AlphaZero,以及它的开源复制品 Leela Chess Zero(它目前在象棋电脑比赛中经常排名第二),它们使用搜索和自学的启发式规则,但不依赖人类的象棋知识。
最近,人工智能系统在扩展方面取得了突破性进展,这使其在认知领域取得了巨大进步,而这些领域对于像「深蓝」这样的早期系统来说仍然具有挑战性。推动这一进步的是通用技术,特别是在专家数据上进行(自)监督训练,并大规模应用基于注意力的架构。在此过程中,研究者们开发出了具有令人印象深刻的认知能力的 LLM,如 OpenAI 的 GPT 系列、LLaMA 模型系列或谷歌 DeepMind 的 Chinchilla 和 Gemini。
然而,目前还不清楚同样的技术是否适用于国际象棋这样的领域,因为在这一领域,成功的策略通常依赖于复杂的算法推理(搜索、动态规划)和复杂的启发式规则。因此,本文的主要问题是:是否有可能利用监督学习来获得一种国际象棋策略,这种策略能很好地泛化到新棋局,而不需要显式搜索?
为了研究这一问题,作者将大规模通用监督训练的成功秘诀应用于国际象棋(见图 1)。
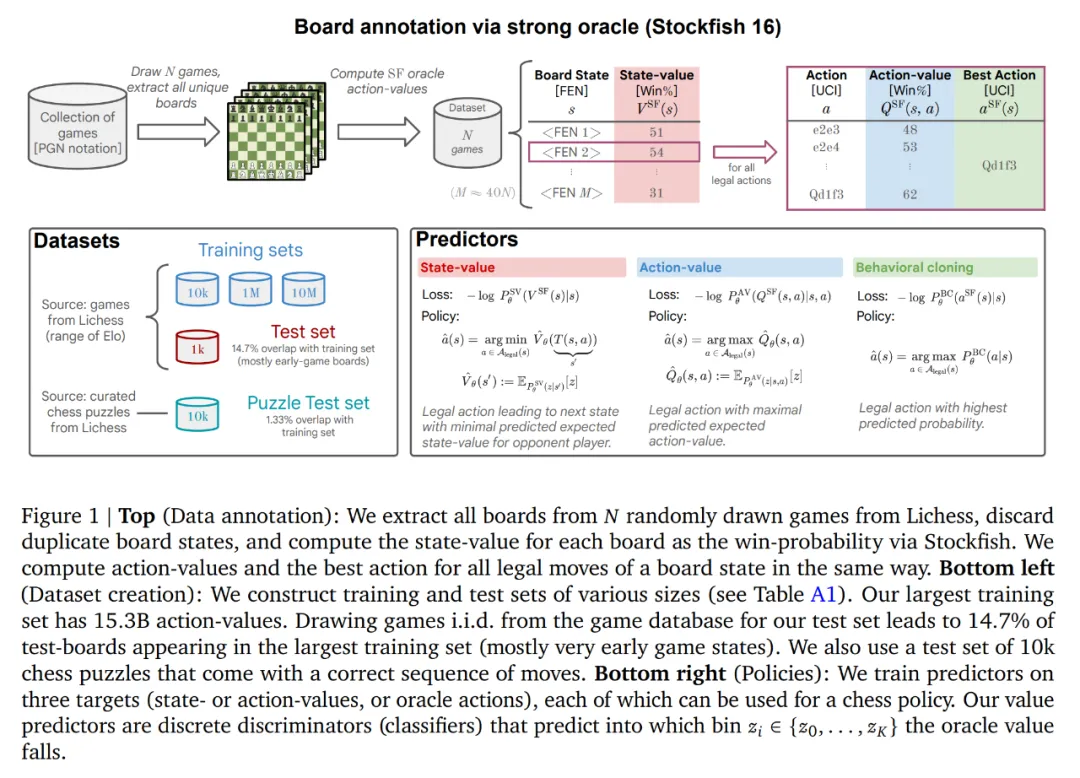
作者使用基于注意力的标准架构和标准监督训练协议来学习预测棋盘的动作 - 值(action-value,对应胜率)。因此,由此产生的国际象棋策略的强度完全取决于底层行动值预测器的强度。
为了获得大量「真实」动作 - 值的数据库,作者使用 Stockfish 16 作为预言机,对数百万个棋盘状态进行注释,这些棋盘状态来自 lichess.org 上随机抽取的人类对弈棋局。正如论文中展示的那样,这将产生一个强大的特级大师级国际象棋策略(在 Lichess 平台上的闪击战中,该模型对阵人类玩家的 Elo 评分为 2895 分)。该策略由一个当代 transformer 驱动,无需任何显式搜索即可预测动作 - 值。该策略优于 GPT-3.5- turbo-instruct(也优于 GPT-4)和 AlphaZero 的策略和价值网络,后者的 Elo 评分分别为 1755、1620 和 1853。
因此,这项工作表明,通过标准监督学习,有可能在足够大的规模上将 Stockfish 16 的良好近似值蒸馏到前馈神经网络中 —— 正如 1921 年至 1927 年国际象棋世界冠军 José Raúl Capablanca 所言:「我只看到前面的一步棋,但它总是正确的一步」。

论文地址:https://arxiv.org/pdf/2402.04494
方法介绍
数据。为了构建数据集,作者从 2023 年 2 月开始在 Lichess (lichess.org) 下载了 1000 万场游戏。并从这些游戏中提取所有棋盘状态 s,并使用 Stockfish 16 估计每个状态的状态值
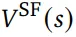
,时间限制为每局 50 毫秒。
方法。对于预测器,作者使用仅有解码器的 transformer 作为主干来参数化离散概率分布,并对 transformer 的输出应用 log-softmax 层进行归一化。因此,模型输出对数概率。
在动作 - 值预测中,上下文大小为 79,而在状态 - 值预测和行为克隆中,上下文大小为 78。对于动作和状态 - 值预测,输出大小为 ,对于行为克隆,输出大小为 1968(所有可能合法动作的数量)。之后作者使用学习到的位置编码,从而保持输入序列的长度是恒定的。最大的模型大约有 2.7 亿个参数。
Token 化。棋盘状态被编码为 FEN 字符串,作者将其转换为固定长度为 77 个字符的字符串,其中每个字符的 ASCII 码即为一个 token。FEN 字符串描述了棋盘上所有棋子的位置、当前轮到哪方、双方玩家的易位、半步计时器和全步计数器。
作者采用 FEN 字符串中任何可变长度的字段,在必要时用填充的方法,将其转换为固定长度的子字符串。对于动作,作者以 UCI 表示法存储动作。为了对其进行 Token 化,作者确定了所有可能的合法动作总共有 1968 个,按字母数字顺序(区分大小写)排序,并取动作的索引作为 token,这意味着动作是由单一 token 描述的。
预测器协议
预测器是离散分布的,根据预测目标,作者将任务分成三类(参见上图 1):动作 - 值预测 (AV, Action-value ) 、 状态 - 值预测 (SV, State-value ) 以及行为克隆 (BC, Behavioral cloning )。
基准
作者将本方法与 Stockfish 16、AlphaZero 的三种变体进行了比较,但并没有和 GPT-4 进行比较,因为他们发现 GPT-4 很难在不做出非法动作的情况下玩完整个游戏。
实验结果
表 1 主要评估了具有 9M、136M 和 270M 参数的三个 Transformer 模型。结果表明,这三个模型都表现出对新棋盘的非凡泛化能力,并且可以成功解决大部分谜题。
在所有指标中,拥有更大的模型可以持续提高得分,这证实了模型规模对于国际象棋表现至关重要。最大的模型在与人类玩家的比赛中取得了 2895 Elo,达到大师级别。

图 2 中作者将 270M 参数模型与 Stockfish 16、GPT-3.5-turbo-instruct 和 AlphaZero 价值网络的性能进行了比较。实验中使用了 10k 个谜题的大型谜题集进行实验。
Stockfish 16 在所有难度类别中表现最佳,其次是本文的 270M 模型。
作者强调,解决谜题需要正确的移动顺序,并且由于本文的策略无法明确提前规划,因此解决谜题序列完全依赖于良好的值估计。
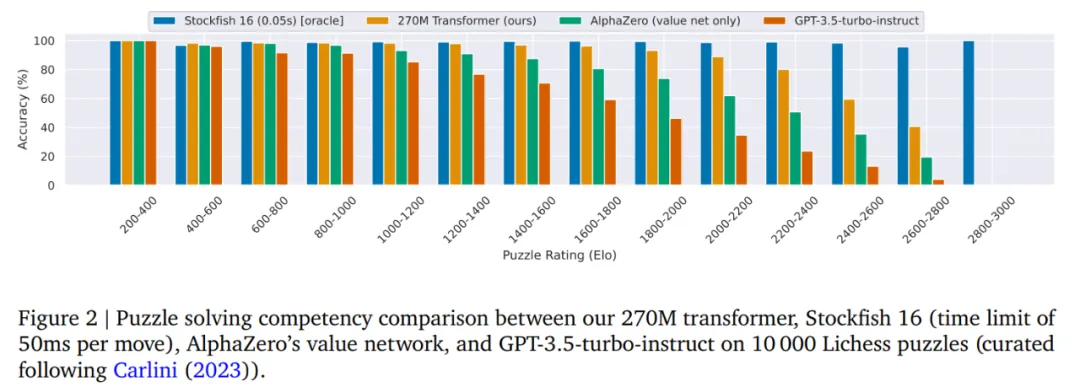
图 3 展示了对数据集和模型大小进行扩展的分析。
对于较小的训练集大小(10k 个游戏),较大的架构(≥ 7M)随着训练的进行开始过度拟合。
当数据集大小增加到 100k 和 1M 场游戏时,这种影响会消失。
结果还表明,随着数据集大小的增加,模型的最终准确率会提高(在模型大小之间保持一致)。同样,作者观察到架构大小增加的总体趋势是无论数据集大小如何,整体性能都会提高。
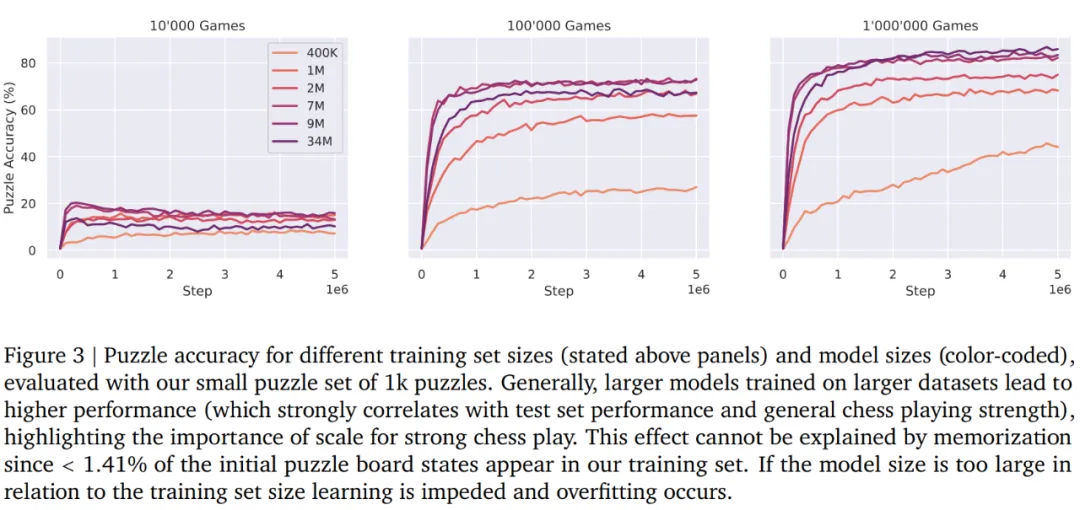
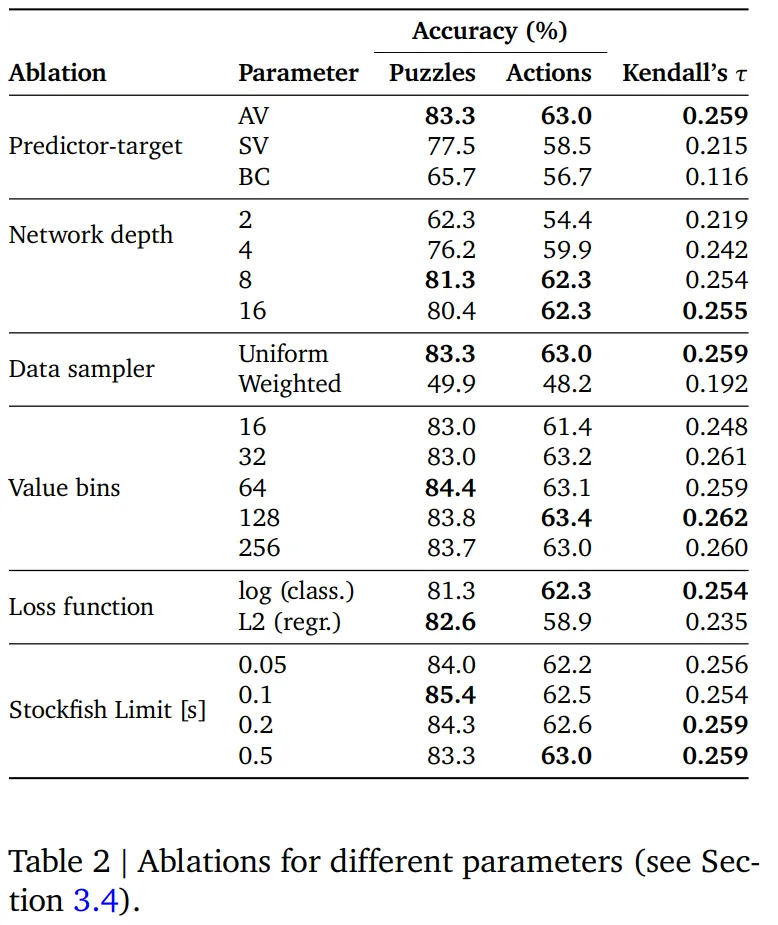
通过下表 2 可以得出以下几点:
动作 - 值预测器在动作排名、动作准确率和谜题准确率方面更胜一筹。
模型的性能随着深度的增加而增加,但似乎在 8 层左右达到饱和,这表明深度很重要,但不能超过某个点。
End

行业解读
利润股价双双暴跌,飞天云动还有出路吗?
黑神话悟空帅爆了,元宇宙的春天也来了!
黑悟空带来的泼天富贵,文旅元宇宙要接住
“寸草不生”的元宇宙土地,还有得救!
两极分化!元宇宙企业进入第二轮“淘汰赛”
元宇宙评测
鹅厂怕不怕?这个社交元宇宙发出挑战
建行元宇宙,让银行业务更便捷了吗?
美踏元宇宙,反差感十足的全新社交平台
我的拾贰世界元宇宙,野心大、噱头更大
城市元宇宙解读
尔滨出圈,看黑龙江硬核布局元宇宙
锚定数字先锋城市,济南如何抢跑元宇宙?
争创中国视谷,杭州元宇宙含金量有多少?
吹响“中国元谷”号角,郑州硬核实力在哪?
争当元宇宙产业第一城,潍坊有什么?
报告精选
《中国元宇宙政策研究报告2023》
《数字中国发展报告(2023年)》
《中国人工智能系列白皮书—元宇宙技术2024》
