

GRA团队 投稿
量子位 | 公众号 QbitAI
无需蒸馏任何大规模语言模型,小模型也能自给自足、联合提升?
上海人工智能实验室联合中国人民大学提出的GRA框架(Generator–Reviewer–Adjudicator) 正是这样一种新范式:
该方法以“多人协作”、“角色分工”的理念为核心,系统性探索了多开源小模型如何通过协同机制生成高质量训练数据。

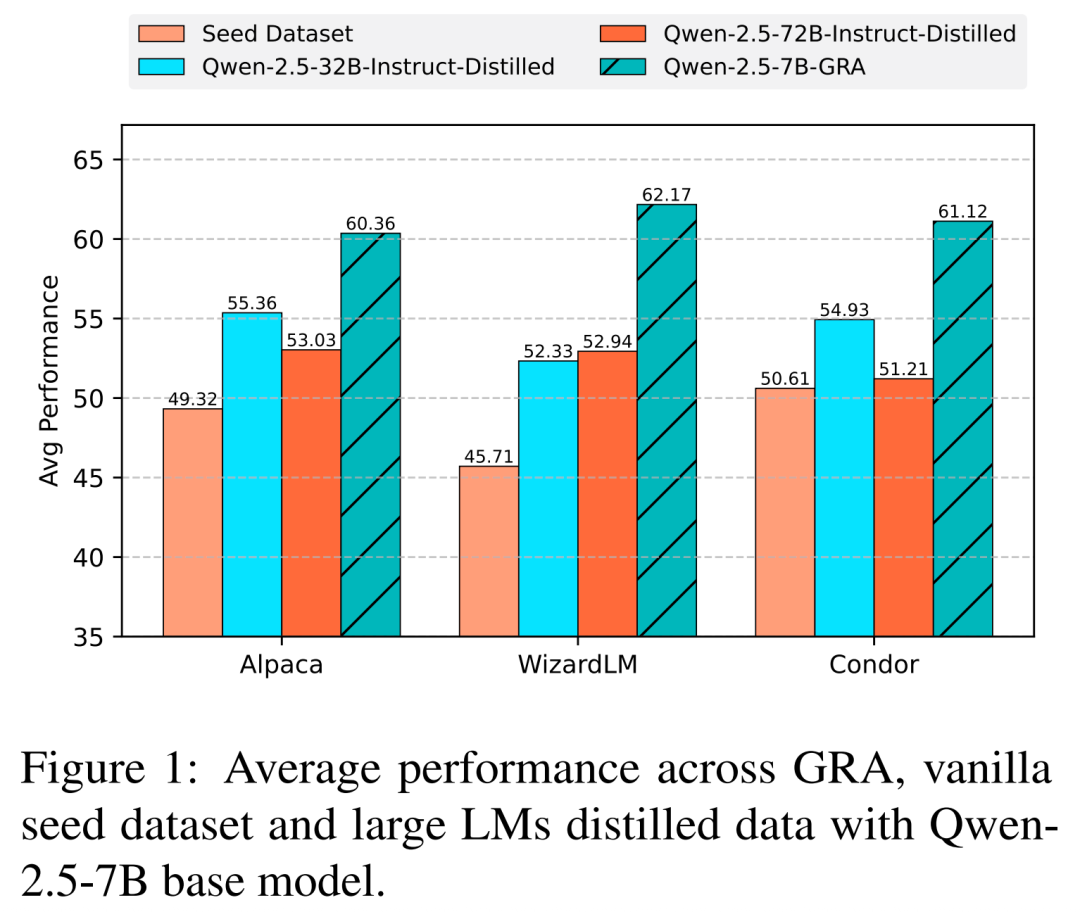
实验结果显示,在涵盖数学、代码、逻辑推理、通识问答等10个主流数据集上,GRA生成的数据质量与单个大型语言模型(如Qwen-2.5-72B-Instruct)输出相当或更高,并在多数任务中取得了显著领先。
该项目已开源,详细可见文末链接。
GRA框架:“模拟论文投稿”

如果说传统方法是单枪匹马生成数据,那GRA更像是一次“模拟顶会审稿流程”——作者、审稿人、AC各就各位,小模型分工合作、打分评审,确保数据内容质量稳定、标准统一。
1.Generator:像“作者”一样创作新样本
GRA会先将任务划分为多个领域(如数学、编程、逻辑推理等),每个Generator小模型负责在对应领域生成新指令与响应。它们从种子数据中提取关键词与摘要,结合领域知识生成高质量样本,确保内容丰富、主题聚焦、语义清晰。
2.Reviewer:像“审稿人”一样严格评审
每条数据生成后,会交由多个Reviewer小模型进行两轮审查:
首先检查指令是否合理、清晰;
然后全面评估响应的正确性、相关性与语言质量,并打分附评语。
系统会根据平均评分与评分一致性筛选样本——分数偏低的直接淘汰,意见分歧的则送入下一环节。
3.Adjudicator:像“AC”一样做出最终裁决
当Reviewer之间出现评分冲突时,Adjudicator小模型将登场,独立复审并做出最终判断。它如同学术审稿中的AreaChair,有效避免“多数误判”,确保留下来的数据客观、可靠。
4.后处理模块:让好数据更“精致”
通过评审后,系统还将进行语义去重、摘要补全与格式统一,进一步提升样本的一致性与表达质量。
总的来说,GRA构建了一个“模拟顶会审稿”的自动化系统:小模型们轮流扮演创作、审阅、仲裁等角色,在多轮协作中生成高质量训练数据。
这种机制不仅提升了数据生成的多样性与公正性,也打破了以往对大模型蒸馏的依赖——实现了真正属于小模型的“集体智能”路径。
实验验证:“三个臭皮匠赛过诸葛亮”
GRA团队选取了覆盖数学推理(如Math、GSM8K)、代码生成(HumanEval、MBPP)、推理问答(HellaSwag、ARC-C、GPQA、BBH)和通识问答(MMLU、IFEval)四个领域的10个公开数据集,以全面评GRA框架的性能。
GRA框架集成了5个参数量在7–8B之间的开源小型语言模型,包括LLaMA-3.1-8B-Instruct、Qwen-2.5-7B-Instruct、InternLM3-8B-Instruct、Mistral-7B-Instruct-v0.3和Tulu-3-8B。
将GRA生成的数据用于训练两个基础模型(LLaMA-3.1-8B-Base和Qwen-2.5-7B-Base),并与原始种子数据以及Qwen-2.5-32B、Qwen-2.5-72B-Instruct蒸馏生成的数据进行了系统对比。
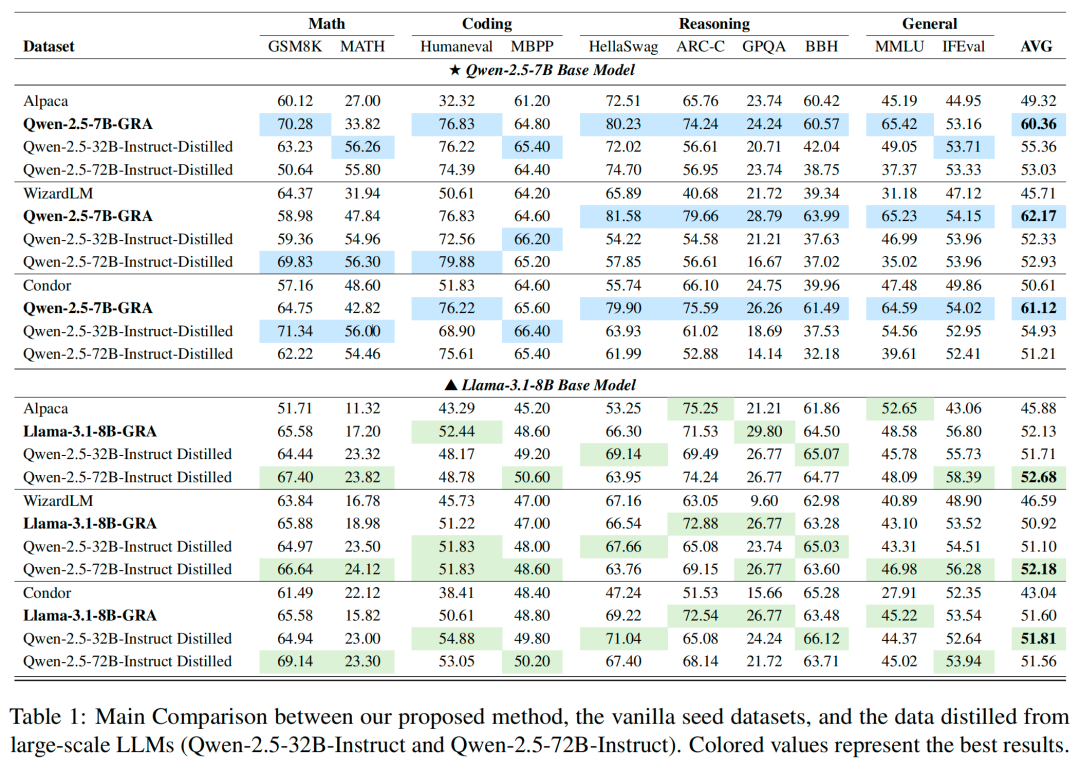
实验核心结果表明:
1.明显优于原始数据:GRA生成的数据在LLaMA-3.1上平均提升了6.18%,在Qwen-2.5上平均提升了11.81%,说明即便在小模型之间协作,GRA也能显著提升数据质量和训练效果。
2.能和大模型蒸馏正面硬刚:GRA在LLaMA-3.1生成数据训练的模型性能,仅比Qwen-72B蒸馏版低0.59%;在Qwen-2.5生成数据训练的模型性能,平均领先Qwen-72B蒸馏版达8.83%。表明小模型协同机制有望成为更低成本、更高性价比的大模型替代方案。
3.大模型“更大”≠更好:实验还发现,Qwen-72B相比32B的性能增幅有限,反映出传统蒸馏范式在进一步扩大参数规模时,收益正逐渐递减。相比之下,GRA的“群体智慧”路径更具扩展潜力。
一句话总结:多个小模型合理分工,也能“卷”出媲美甚至超越大模型的训练效果。这不仅节省算力,更可能重塑我们对“什么才是有效数据合成”的认知。
要素分析:“1+1+1>3”
从数据多样性、质量、难度控制等维度对GRA的优势进行分析,发现以下关键因素:
1.数据多样,补充盲区
通过t-SNE可视化对比发现,GRA生成的数据分布明显比原始种子数据和大模型蒸馏数据更广、更均匀,尤其在原始数据未覆盖的语义空间中表现出良好的补充能力。这表明GRA所产数据具备更强的覆盖面和多样性。
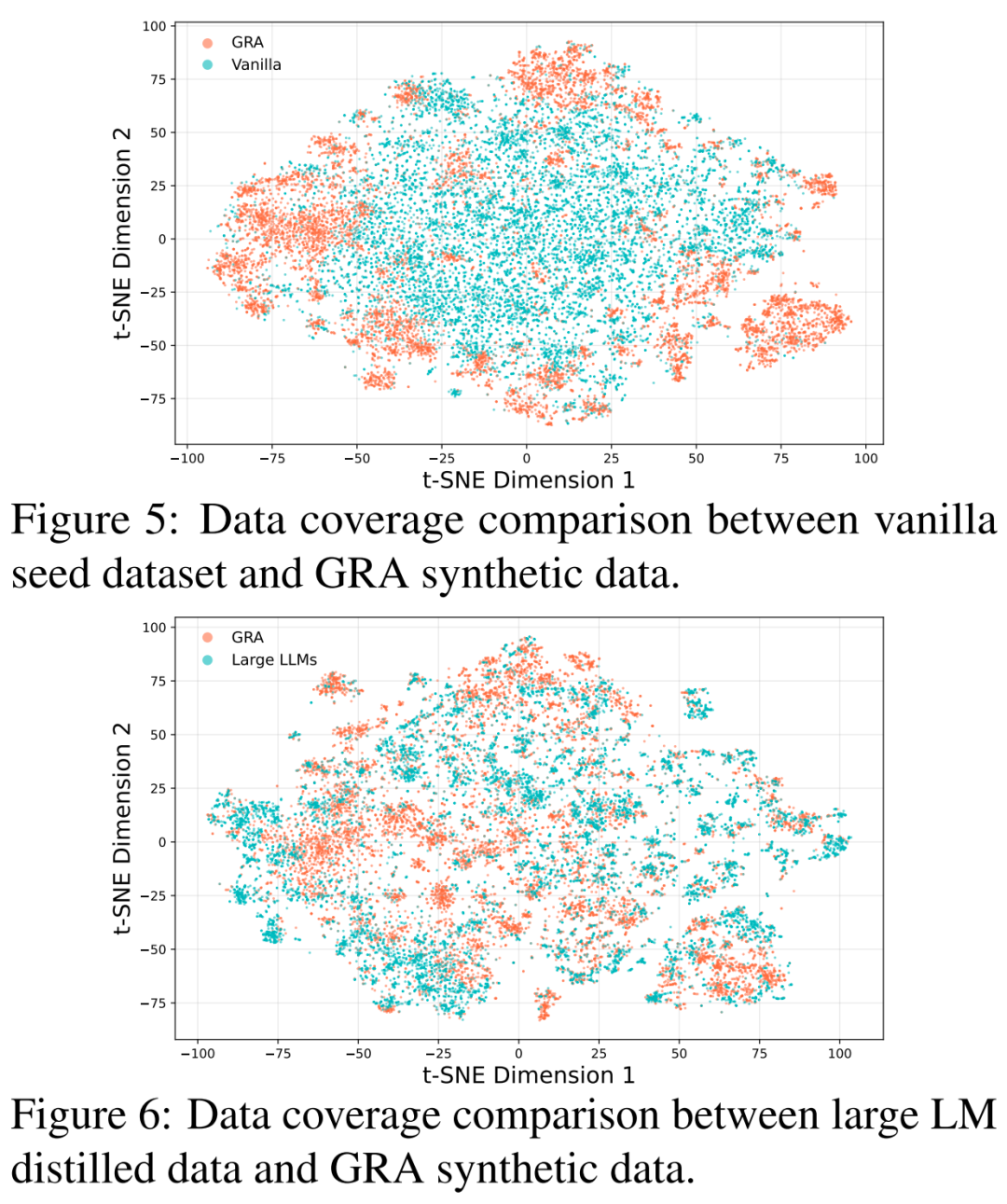
2.数据质量靠谱,审得细也审得稳
GRA生成的数据不仅通过多个小模型评审,还在对比实验中获得了来自Qwen-2.5-72B的高分认可——其中超过87.3%的样本评分高度一致。
同时,GRA的评分体系呈现出更平滑、细腻的分布,表明其在数据质量评估中具备更强的分辨力和一致性,验证了其数据筛选机制的可靠性。

3.数据更“难啃”,训练更有效
通过Instruction-Following Difficulty(IFD)指标分析,GRA生成数据的任务难度比种子数据高出14.58%,并且与大模型蒸馏数据基本持平(GRA:75.82%,Qwen-72B蒸馏:75.49%)。这意味着GRA能够构建具挑战性、高知识密度的数据,为小模型提供更具张力的训练样本。

论文地址:https://arxiv.org/abs/2504.12322
项目地址:https://github.com/GX-XinGao/GRA
模型地址:https://huggingface.co/collections/GX-XinGao/gra-6801cba58ceb0074566cdb4e
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

点亮星标
科技前沿进展每日见