


本文介绍的工作由中国人民大学高瓴人工智能学院李崇轩、文继荣教授团队与蚂蚁集团共同完成。朱峰琪、王榕甄、聂燊是中国人民大学高瓴人工智能学院的博士生,导师为李崇轩副教授。
该研究基于团队前期发布的 8B 扩散语言模型 LLaDA(国内率先做到真正可用的扩散语言模型,是后续很多研究的主干基础模型),探索了扩散语言模型的偏好对齐方法,提出了方差缩减的偏好优化方法 VRPO,并利用 VRPO 对 LLaDA 进行了强化对齐,推出了 LLaDA 1.5。与 LLaDA 相比,LLaDA 1.5 在数学、代码和对齐任务上取得了一致性的提升。同时,VRPO 为后续扩散语言模型的对齐提供了统一的框架。
近期,扩散语言模型受到广泛关注,催生了一系列针对该领域的探索性研究,随着 Gemini Diffusion 的发布,这一趋势进一步加速。
然而,现有的大型扩散语言模型多采用「预训练 + 有监督微调」的范式,针对扩散语言模型的强化对齐进行深入研究的工作较为有限。
强化对齐对于大语言模型的指令遵循和通用任务能力至关重要。研究团队以直接偏好优化(DPO)为切入点,剖析了扩散语言模型在强化对齐时面临的关键问题,提出了方差缩减的偏好优化方法,使扩散语言模型能够实现稳定的强化对齐训练,这一原则也为后续扩散语言模型的对齐工作提供了理论基础和实践指南。

论文标题:LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
论文链接:https://arxiv.org/abs/2505.19223
项目地址:https://ml-gsai.github.io/LLaDA-1.5-Demo/
性能表现:数学、代码、对齐任务相比 LLaDA 取得一致性提升
相比于 LLaDA,LLaDA 1.5 在数学、代码生成、对齐任务上取得了一致性的提升。
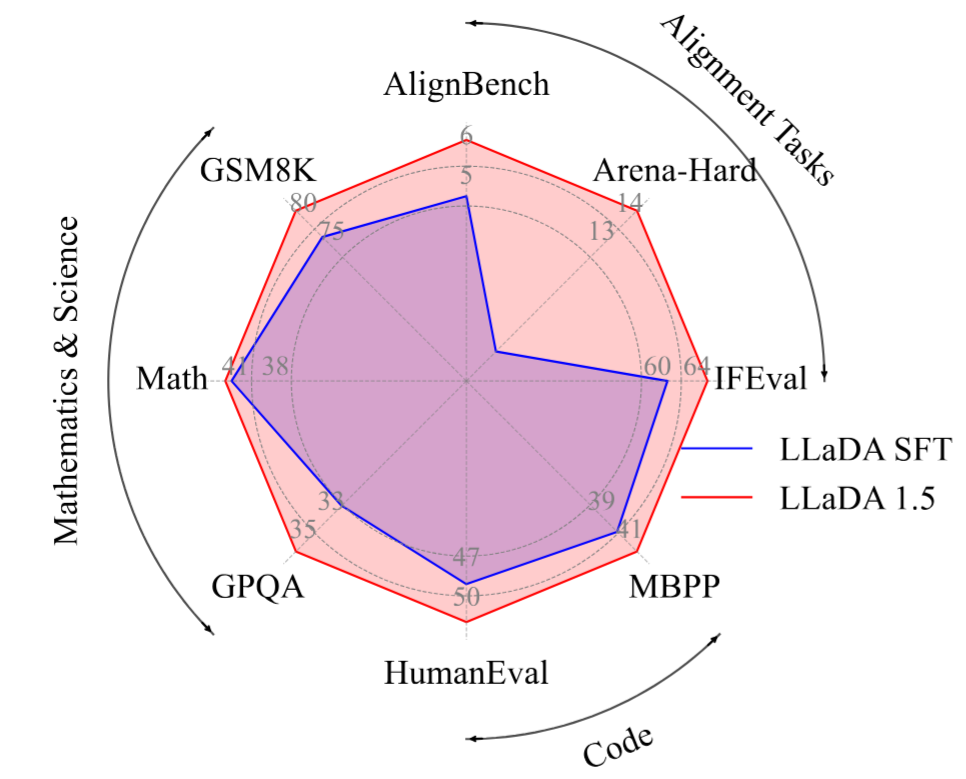
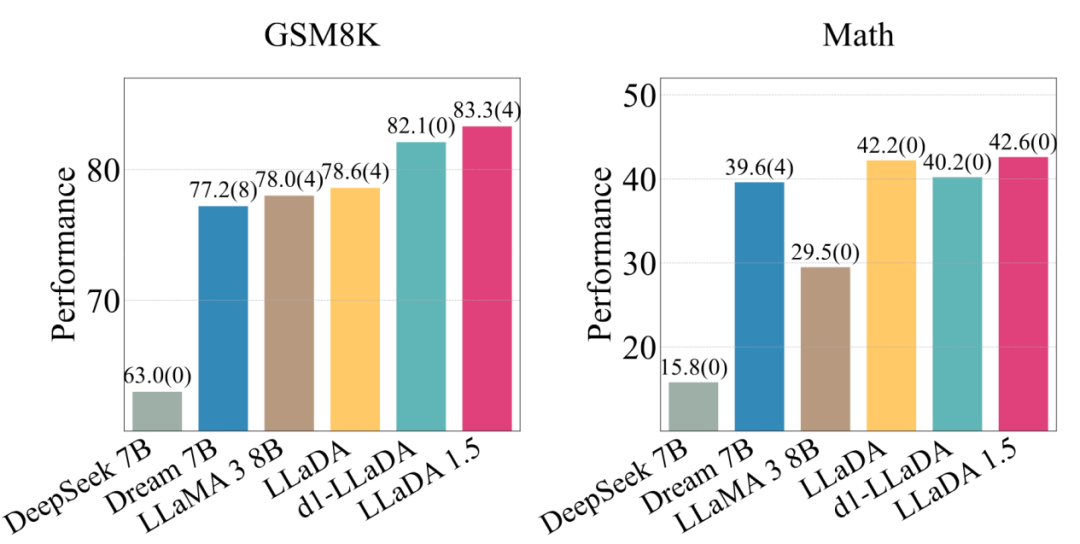
此外,LLaDA 1.5 是当前最具有竞争力的扩散语言模型。与其他扩散语言模型相比,在数学任务(如 GSM8K,Math)上具有竞争性优势。
相比于 LLaDA,LLaDA 1.5 在指令遵循能力上的提升显著:

上述指令给出了对模型的一系列要求:提出两种新型补品的名字并包含关键词「brand」,名称以双尖括号标注,先逐词复述请求,再给出答案。相比 LLaDA,LLaDA 1.5 遵循了全部指令。
方法介绍
该研究以直接偏好优化(DPO)为切入点,原始 DPO 损失基于模型对给定偏好数据对的对数似然。对于掩码扩散语言模型,难以计算精确的对数似然,使用证据下界(ELBO)近似。需要通过对时间步 t 和掩码数据 y_t 进行双重采样进行估计:
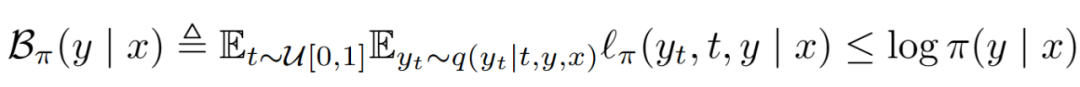
将 ELBO 带入 DPO 损失的对数似然项,可以得到基于 ELBO 的 DPO 损失估计器:
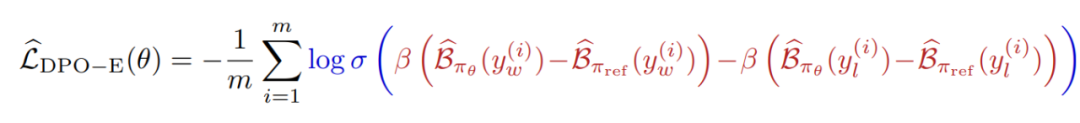
其中,红色部分为偏好估计。
在实际应用中,采用蒙特卡洛方法近似对数似然会引入 DPO 损失的偏差和方差,影响模型的梯度估计,进而导致训练过程不稳定,甚至影响模型对齐后的最终性能表现。
本研究首先证明了:蒙特卡洛估计引入的偏差和方差,可以被偏好估计器的方差限制;降低偏好估计器的方差可以分解为降低 ELBO 估计的方差,以及提高 π_θ 和 π_ref 的 ELBO 估计之间的相关性。据此,本研究提出并证明了以下方差缩减策略的有效性:
提高蒙特卡洛估计的采样预算;提高采样预算能够降低 ELBO 估计的方差。
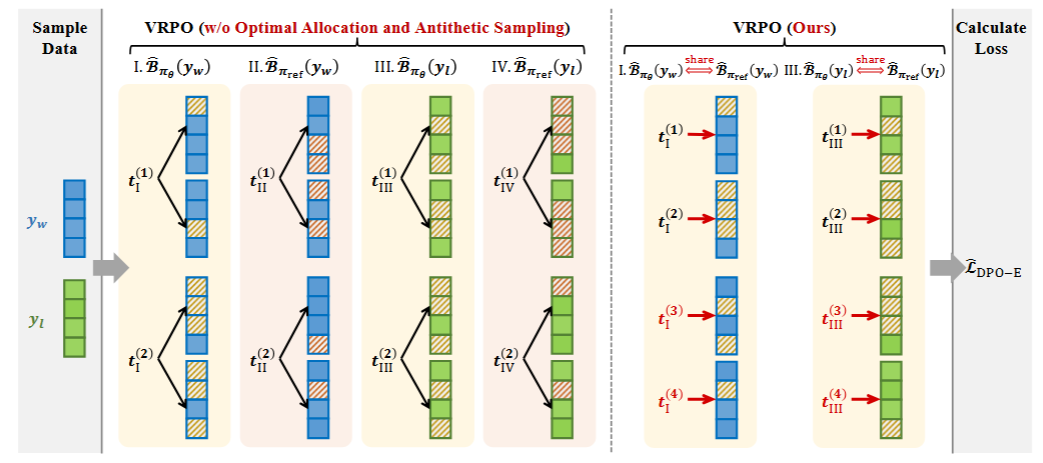
给定总采样预算的最优分配策略;在给定总采样预算 n=n_t×n_(y_t) 下,当采样预算分配为采样 n 个时间步、每个时间步采样一个加噪样本时,ELBO 估计的方差达到最小。
对偶采样策略。通过增加 π_θ 和 π_ref 所使用噪声样本之间的相关性,能够进一步降低梯度估计的方差。具体而言,在 ELBO 估计中,对于 π_θ 和 π_ref,应当共享相同的偏好数据的噪声样本和拒绝数据的噪声样本。
综合上述策略,最终得到的方差缩减的偏好优化方法如下右图。对于每一个偏好数据对,在给定的采样预算 n 下,采样 n_t=n 个时间步,对于每个时间步采样 1 个噪声样本,并在 π_θ 和 π_ref 间共享噪声样本,以进行高效偏好估计。
总结与展望
本研究围绕扩散语言模型的偏好对齐任务,提出了方差缩减的偏好优化方法 VRPO,并从理论分析与实际实验两方面系统论证了该方法在有效降低梯度估计方差、提升模型对齐效果上的优越性。基于 VRPO 优化的 LLaDA 1.5 模型,在数学推理、代码生成、模型对齐等多个任务上均实现了全面且稳定的性能提升,验证了方法的通用性和有效性。
本研究提出的方差缩减算法 VRPO 主要以 DPO 为分析对象,但所提出的方法具有普适性,可被推广应用到其他涉及 ELBO 估算或强化对齐的算法中,为扩散语言模型在强化对齐领域构建了统一的理论与方法框架。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com