

编辑:杜伟
在开源模型领域,DeepSeek 又带来了惊喜。
上个月 28 号,DeepSeek 来了波小更新,其 R1 推理模型升级到了最新版本(0528),并公开了模型及权重。
这一次,R1-0528 进一步改进了基准测试性能,提升了前端功能,减少了幻觉,支持 JSON 输出和函数调用。
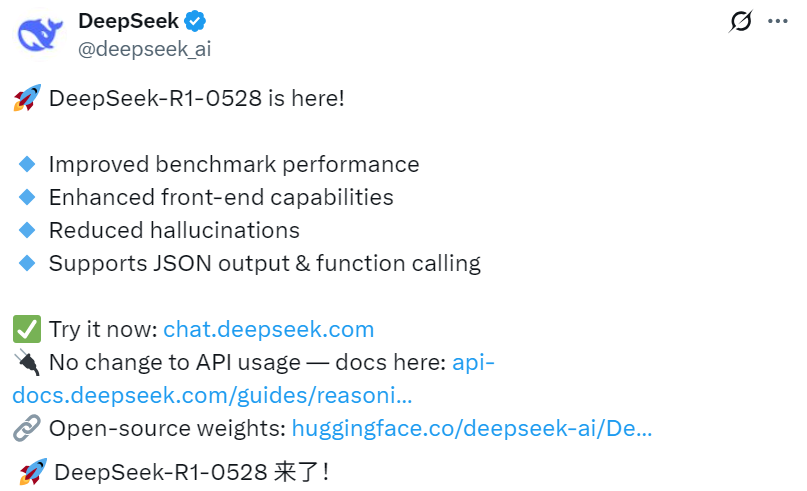
今天,业界知名、但近期也陷入争议(曾被指出对 OpenAI、谷歌及 Meta 的大模型存在偏袒)的大模型公共基准测试平台 LMArena 公布了最新的性能排行榜,其中 DeepSeek-R1(0528)的成绩尤为引人瞩目。
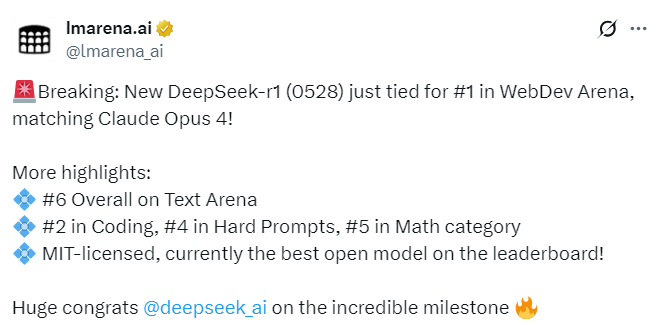
其中,在文本基准测试(Text)中,DeepSeek-R1(0528)整体排名第 6,在开放模型中排名第一。

具体到以下细分领域:
在硬提示词(Hard Prompt)测试中排名第 4
在编程(Coding)测试中排名第 2
在数学(Math)测试中排名第 5
在创意性写作(Creative Writing)测试中排名第 6
在指令遵循(Intruction Fellowing)测试中排名第 9
在更长查询(Longer Query)测试中排名第 8
在多轮(Multi-Turn)测试中排名第 7

此外,在 WebDev Arena 平台上,DeepSeek-R1(0528)与 Gemini-2.5-Pro-Preview-06-05、Claude Opus 4 (20250514) 等闭源大模型并列第一,在分数上更是超过了 Claude Opus 4。
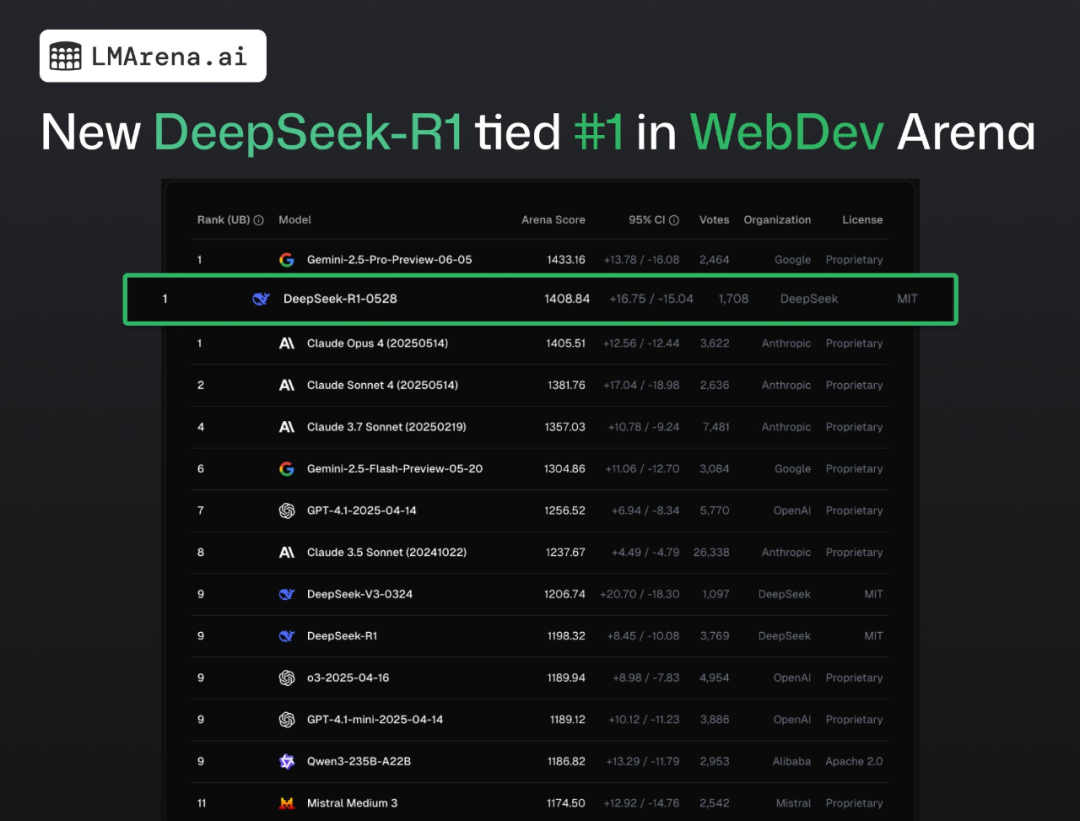
WebDev Arena 是 LMArena 团队开发的实时 AI 编程竞赛平台,让各家大语言模型进行网页开发挑战,衡量的是人类对模型构建美观且功能强大的 Web 应用能力的偏好。
DeepSeek-R1(0528)表现出来的强大性能激起了更多人使用的欲望。
还有人表示,鉴于 Claude 长期以来一直是 AI 编程领域的基准,如今 DeepSeek-R1(0528)在性能上与 Claude Opus 相当,这是一个里程碑时刻,也是开源 AI 的关键时刻。
DeepSeek-R1(0528)在完全开放的 MIT 协议下提供了领先的性能,并能与最好的闭源模型媲美。虽然这一突破在 Web 开发中最为明显,但其影响可能延伸到更广泛的编程领域。
不过,原始性能并不能定义现实世界的表现。虽然 DeepSeek-R1(0528)在技术能力上可能与 Claude 相当,但其是否可以在日常工作流程中提供媲美 Claude 的用户体验,这些需要更多的实际验证。

高强度使用过 DeepSeek-R1(0528)的小伙伴,可以在评论区留言,谈一谈自己的体验感受。
参考链接:
https://lmarena.ai/leaderboard/text
https://x.com/lmarena_ai/status/1934650639906197871
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com