

编辑:泽南、杜伟
大模型不会照搬训练数据中的数学推理,回答事实问题和推理问题的「思路」也不一样。
大语言模型的「推理」能力应该不是推理,在今年 6 月,一篇 Nature 论文《Language is primarily a tool for communication rather than thought》曾引发 AI 社区的大讨论,改变了我们对于 AI 智力的看法。
该论文认为人类语言主要是用于交流的工具,而不是思考的工具,对于任何经过测试的思维形式都不是必需的。图灵奖获得者 Yann LeCun 对此还表示,无论架构细节如何,使用固定数量的计算步骤来计算每个 token 的自回归 LLM 都无法进行推理。
那么,大模型的「推理」行为到底是在做什么呢?本周四,一篇来自伦敦大学学院(UCL)等机构的研究《Procedural Knowledge in Pretraining Drives Reasoning in Large Language Models》详细探讨了大语言模型(LLM)在执行推理任务时采用的泛化策略类型,得出的结论给我们了一些启发。
大模型的「推理」是在做什么?
一个普遍的猜测是:大模型的推理难道是在从参数知识中检索答案?该研究给出了反对这一观点的证据。作者认为,是预训练中的程序性知识在推动大模型进行推理。
自从大模型出现以来,AI 研究领域一直流传着这样一种假设:当大模型在进行推理时,它们进行的是某种形式的近似检索,即从参数知识中「检索」中间推理步骤的答案,而不是进行「真正的」推理。
考虑到大模型所训练的数万亿个 token、令人印象深刻的记忆能力、评估基准的数据污染问题已得到充分证实,以及大模型推理依赖于 prompt 的性质,这种想法看起来似乎是合理的。
然而,大多数研究在得出结论认为模型不是真正推理时,并没有进一步去研究预训练数据。在新的工作中,人们希望探索一个命题:即使推理步骤的答案就在数据中,模型在生成推理轨迹时是否会依赖它们?
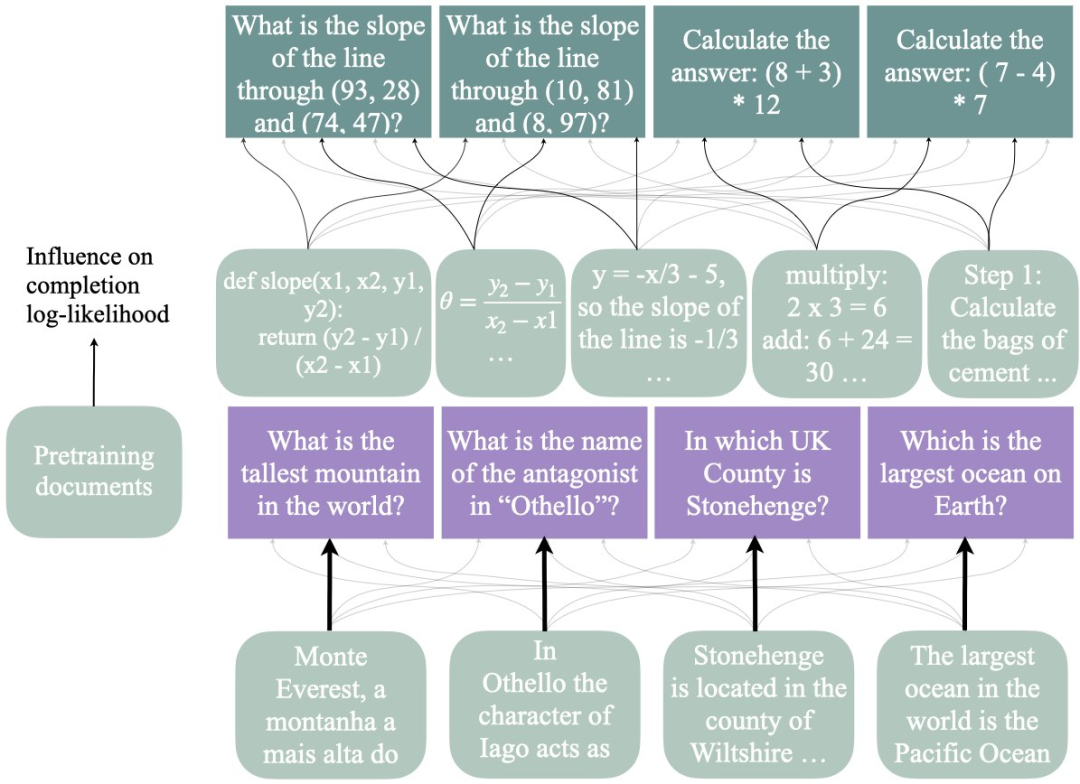
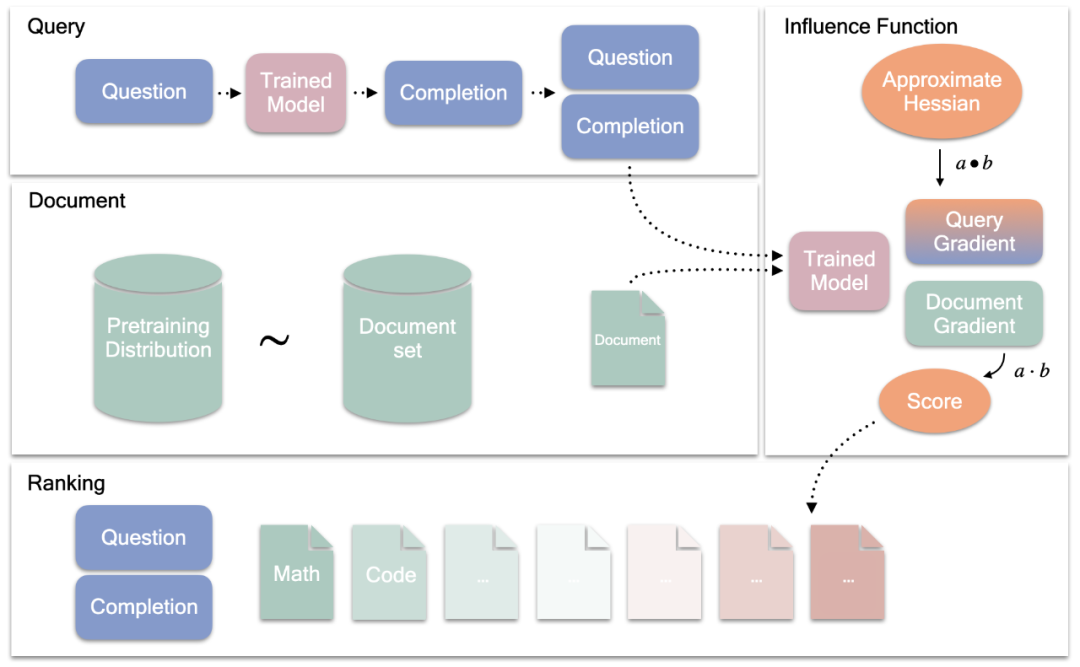
作者使用影响函数来估计预训练数据对两个 LLM(7B 和 35B)完成事实问题回答(下图左)的可能性,以及简单数学任务(3 个任务,其中一个显示在右侧)的推理轨迹的影响。

令人惊讶的是,研究发现的结果与我们的想法相反:LLM 使用的推理方法看起来不同于检索,而更像是一种通用策略——从许多文档中综合程序性知识并进行类似的推理。
新论文的一作、UCL 在读博士 Laura Ruis 表示,该研究是基于对 5M 预训练文档(涵盖 25 亿个 token)对事实问题、算术、计算斜率和线性方程的影响的分析。总而言之,他们为这项工作做了十亿个 LLM 大小的梯度点积。
接下来还有几个问题:大模型是否严重依赖于特定文档来完成任务,或者文档是更有用,还是总体贡献较少?前者适合检索策略,后者则不适合。
通过实验可以看到,模型在生成推理痕迹时对单个文档的依赖程度低于回答事实问题(下图箭头粗细表示)时对单个文档的依赖程度,并且它们所依赖的文档集更具通用性。
对于事实问题,答案往往表现出很大的影响力,而对于推理问题则不然(见下图底行)。此外,该研究发现的证据表明代码对推理既有正向影响,也有反向的影响。
另外,看文档对查询推理轨迹的影响可以较容易地预测出该文档对具有相同数学任务的另一个查询的影响,这表明影响力会吸收文档中用于推理任务的程序性知识。
因此可以得出结论,大模型通过应用预训练期间看到的类似案例中的程序性知识(procedural knowledge)进行推理。这表明我们不需要在预训练中涵盖所有可能的案例——专注于高质量、多样化的程序数据可能是更有效的策略。
该研究可能会改变我们对于 LLM 推理的看法。Laura Ruis 表示,很期待见证这种程序泛化风格的发现,对于更大的模型,或潜在的不同预训练数据分割等方向的影响。

论文链接:https://arxiv.org/abs/2411.12580
实验设置
模型选择
研究者选择了两个不同体量的模型(7B 和 35B),分别是 Cohere 的 Command R 系列的基础和监督微调版本。其中,他们使用基础模型估计二阶信息并计算文档梯度,并使用监督指令微调模型生成完成并计算查询梯度。
查询设置
研究者收集了一个包含不同类型问题的查询集,其中 40 个推理问题,40 个事实问题。
对于推理问题,他们确定了两种数学推理类型,每种模型都可以使用零样本 CoT 来稳健地完成。研究者在包含每种推理类型的 100 个问题的更大集合上对模型进行评估,并选择了至少 80% 正确率的任务。
这为 7B 模型提供了简单的两步算法(如下表 1 所示),并为 35B 模型求解线性方程中的 x(如下表 9 所示)。研究者确保没有查询需要输出分数。并且,为了使 7B 和 35B 模型之间的结果更具可比性,他们对这两个模型使用了相同的斜率问题。


对于 40 个事实问题,研究者确保模型一半回答正确,一半错误,从而能够识别从参数知识中检索事实的失败。
文档设置
研究者想要比较预训练数据对不同大小模型(7B 和 35B)推理的影响,因此他们选择了两个在相同数据上训练的模型。其中,每个模型只需要对 Hessian 进行一次 EK-FAC 估计,但公式 1 中的其他项要求每个文档 - 查询对通过模型进行两次前向和后向传递。
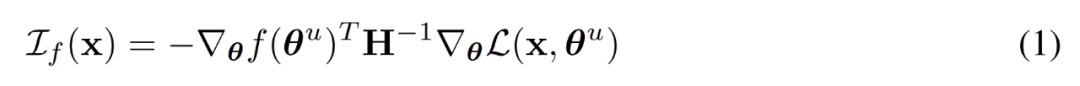
为了解决这个问题,研究者从预训练数据中抽取了一组文档,这些文档涵盖了预训练期间看到的每个批次的多个示例,总共 500 个文档(约 25 亿 token),其分布与训练分布相似。
EK-FAC 估计
为了估计 7B 和 35B 模型的 Hessian,研究者通过对两个模型进行预训练,随机抽取了 10 万份均匀分布的文档。
实验结果:五大发现
为了回答上述关于 LLM 推理泛化的问题,研究者进行了定量和定性分析,并得出了以下五大发现。
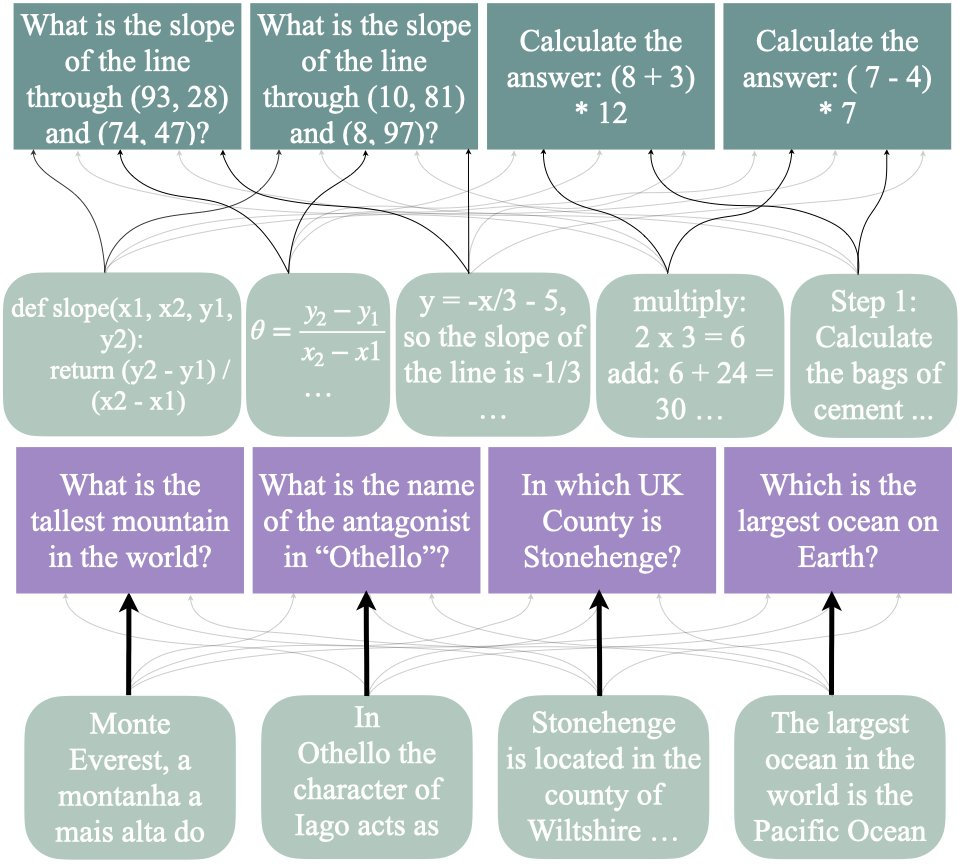
发现 1:对于具有相同底层推理任务的查询,文档的影响力得分之间存在显著的正相关性,表明了这些文档与「需要对不同数字应用相同程序」的问题相关。
研究者计算了所有 500 万个文档得分对于所有查询组合的 Pearson R 相关性(每个模型有 802 个相关性)。下图右显示了每个任务 10 个查询的子样本结果。
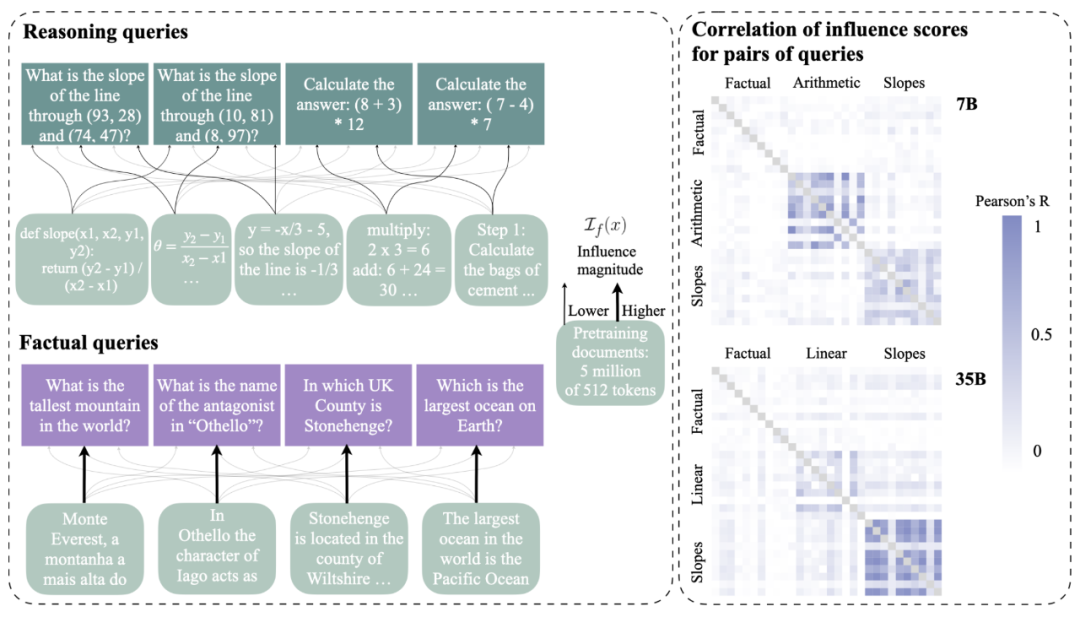
他们还发现,相同推理类型的很多查询之间存在非常显著的正相关性(p 值均低于 4e - 8),而大多数(但不是全部)事实查询或其他组合(例如不同类型的推理查询)之间存在非常显著的相关性缺失(p 值均在 4e - 3 左右)。这意味着许多文档对同一类型的推理具有类似的影响。

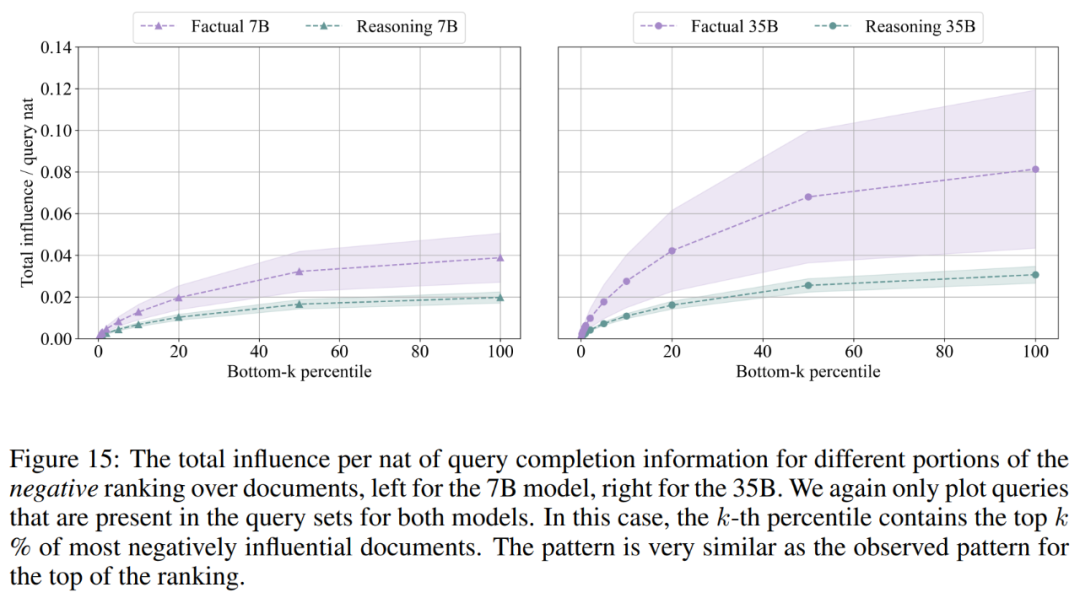
发现 2:在推理时,模型对每个文档的依赖程度平均低于回答事实问题时对每个生成信息量的依赖程度,总体影响幅度波动性要小得多,表明它是从一组更一般的文档中泛化出来的。模型越大,效果越明显。下图 2 展示了对排名中不同百分数正向部分的总影响。
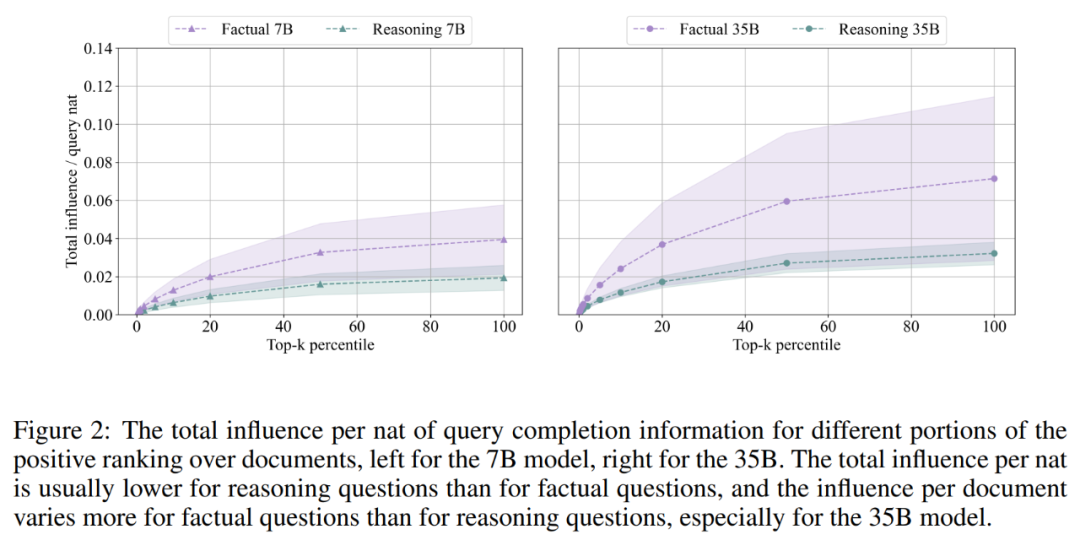
结果描述了 top-k 百分位正向排名文档中包含的总影响力,比如第 20 个百分数包含了一个查询的 20% 正向文档,显示的总影响力是截止到该部分排名的所有文档影响力的总和。
发现 3:事实问题的答案在对问题 top 影响力的文档中出现的频率相对较高,而推理问题的答案几乎没有在对它们 top 影响力的文档中出现过。

如下图 3 所示,对于 7B 模型,研究者在 55% 的事实查询的前 500 个文档中找到了答案,而推理查询仅为 7.4%。对于 35B 模型,事实查询的答案在 top 影响力文档中出现的概率为 30%,而推理集的答案从未出现过。
发现 4:对推理查询有影响力的文档通常采用类似的逐步推理形式,如算术。同时有影响力的文档通常以代码或一般数学的形式实现推理问题的解决方案。
总的来说,研究者在 top 100 份文档中手动找到了 7 个以代码实现斜率的独特文档,以及 13 个提供计算斜率方程式的文档。其中,7B 模型依赖其中 18 个文档来完成其补全(这意味着 18 个不同的文档出现在所有查询的 top 100 份文档中),而 35B 模型则依赖 8 个文档。
下图分别是一个以 JavaScript(左)和数学(右)实现解决方案的极具影响力的文档示例。

发现 5:对于事实查询,最有影响力的数据来源包括维基百科和小知识;而推理查询的主要来源包括数学、StackExchange、ArXiv 和代码。
总而言之,该研究结果表明,LLM 实际上可以从预训练数据中学习一种通用的推理方法,并且可以从数据中的程序性知识中学习。此外,人们发现没有任何证据表明模型依赖于预训练数据中简单数学推理步骤的答案。这意味着近似检索假设并不总是正确的,这对未来人工智能的设计具有重要意义。
也就是说,我们可能不需要专注于覆盖预训练数据中的每种情况,而是可以专注于数据应用和演示各种推理任务的程序。
这份研究结果表明,LLM 实际上可以从预训练数据中学习一种通用的推理方法,并且可以从数据中的程序性知识中学习。此外,人们没有发现任何证据表明模型依赖于预训练数据中简单数学推理步骤的答案。这意味着近似检索假设并不总是正确的,这对未来 AI 的设计具有意义。
也就是说,我们可能不需要专注于覆盖预训练数据中的每种情况,而是可以专注于数据应用和演示各种推理任务的程序。
更多技术细节与实验结果请参阅原论文。
参考内容:
https://www.reddit.com/r/MachineLearning/comments/1gvveu8/r_procedural_knowledge_in_pretraining_drives/
https://lauraruis.github.io/2024/11/10/if.html
https://x.com/LauraRuis/status/1859267739313185180
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com