

智东西11月20日报道,LLM基准测试项目LiveBench官网最新榜单显示,中国大模型“六小虎”之一阶跃星辰的大语言模型step-2-16k-202411,总评分位列全球第五、国产第一。同时,在六类别任务中,step-2-16k-202411的指令跟随(IF Average)评分排名第一,比OpenAI的o1-preview-2024-09-12更高。
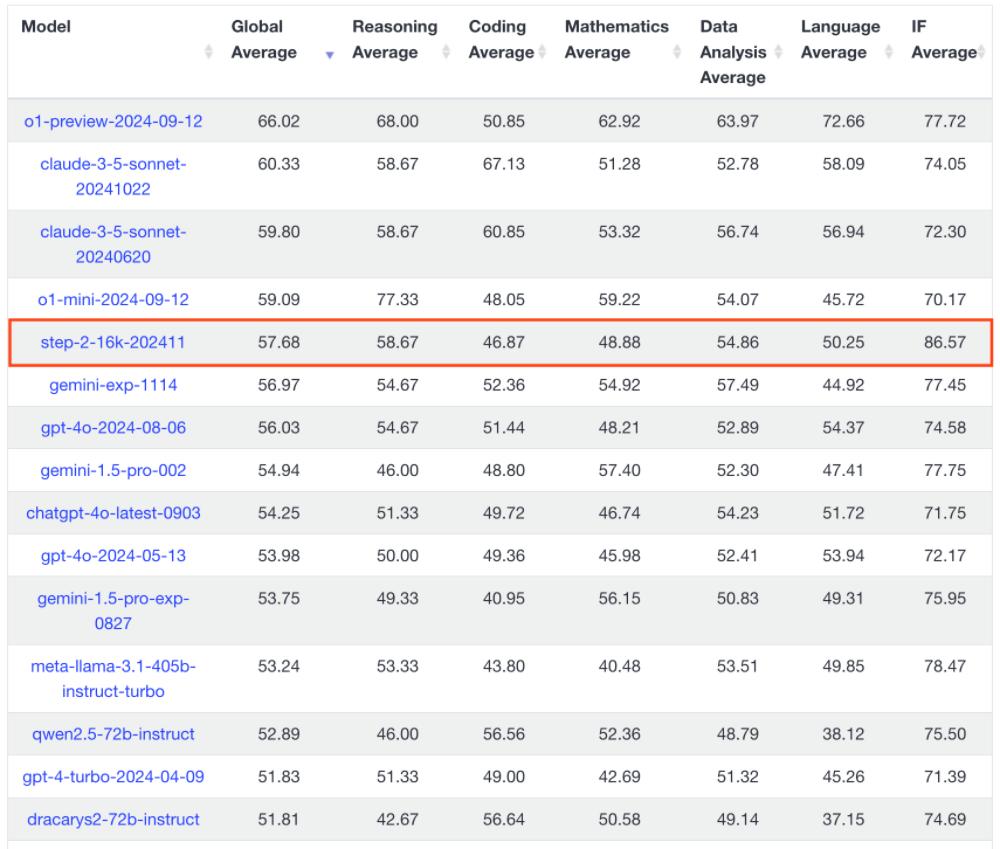
▲LiveBench榜单总评分前15名
LiveBench项目由Abacus.AI主导,图灵奖得主、Meta首席AI科学家杨立昆(Yann Lecun)参与其中,因其每月更新问题、评分体系客观,被业内称为“最难糊弄的LLMs基准测试”。
成功挑战LiveBench的step-2-16k-202411,是阶跃星辰自研的万亿参数MoE大语言模型。在设计Step-2 MoE架构时,阶跃星辰放弃upcycle(向上复用)路径,选择从头开始训练,通过部分专家共享参数、异构化专家设计等方式创新MoE架构设计。今年3月,Step-2预览版发布,成为国内首个由创业公司发布的万亿参数MoE大语言模型。
目前,阶跃星辰已发布包括万亿MoE大语言模型Step-2、多模态理解大模型Step-1.5V、图像生成模型Step-1X在内的Step系列模型 “全家桶”,以及C端应用“跃问”和“冒泡鸭”。
基准测试是大模型的“高考”,考试成绩在很大程度上影响了大模型的应用和商业价值。如今基准测试五花八门,LiveBench的评分结果为什么如此具有参考价值?行业日新月异,在众多国产大模型中,为什么阶跃星辰得以闯入世界级赛场,和OpenAI、Anthropic同台竞技?通过拆解LiveBench榜单以及阶跃星辰的大语言模型Step-2,我们找到了答案。
01.国产大模型与OpenAI同台竞技
今年6月中旬,LiveBench项目正式发布,项目团队在创始博客中给它下了个定义——“具有挑战性、无污染的LLM基准测试(A Challenging, Contamination-Free LLM Benchmark)”,项目参与方名单里,杨立昆、纽约大学、英伟达、南加州大学等在AI领域颇具话语权和关注度的主体赫然在列。
▲LiveBench官网博客
除了诸多著名的参与方,LiveBench更受业界关注的特点是,在设计时考虑了测试集污染问题,尽可能保证评分结果的客观真实。具体而言:
1、它们根据最新发布的数据集、arXiv论文、新闻报道和IMDb电影概述设计问题,每月更新题库,以此来限制潜在的污染,防止大模型在回答时作弊;
2、保证每个问题都有可验证的、客观真实的答案,可以对难题进行精确、自动评分,不通过LLM评分,避免落入LLM的判断陷阱,如对自己答案的偏见以及对答案的错判;
3、目前包含推理、编码、数学、数据分析、语言理解、指令跟随等六个类别、18项任务,并将随着时间的推移发布更新、更难的任务。
简而言之,LiveBench每月都用全新题库考验各家大模型,并在无人工、无大模型参与评分的情况下进行更为准确、客观的排名。
就是在这样一个颇具权威性和公平性的基准测试中,阶跃星辰的step-2-16k-202411位列全球第五,也是榜单前十中唯一一个国产大模型。
LiveBench榜单第一到第四名分别是o1-preview-2024-09-12、claude-3-5-sonnet-20241022、claude-3-5-sonnet-20240620、o1-mini-2024-09-12,被OpenAI和Anthropic两家美国AI独角兽占据,之后便是阶跃星辰的step-2-16k-202411;谷歌的gemini-exp-1114排名第六位。
从任务类别来看,step-2-16k-202411在指令跟随(IF,Instruction Following)方面以86.57的评分位列第一,排名第二的是谷歌的大模型gemini-1.5-flash-002,评分为84.55,在阶跃星辰之后。
根据LiveBench介绍,指令跟随类别包括四项子任务,即在遵循一个或多个指令,如字数限制或在答案中加入特定元素的基础上,根据《卫报》的最新报道,解释、简化、总结或生成故事。step-2-16k-202411在该类别的高得分,展现了其在语言生成上对细节有超强的控制力,能够更好地理解和遵循人类指令。
02.放弃捷径,Step-2创新MoE架构从头开始
阶跃星辰Step-2的高排名源于团队对算法架构的创新。
今年3月,Step-2预览版发布,成为国内首个由创业公司发布的万亿参数模型;7月世界人工智能大会上,Step-2正式发布,当时在数理逻辑、编程、世界知识、指令跟随等方面体感就全面逼近GPT-4。
具体而言,Step-2具备出色的理解能力,能够从上下文中推断出用户的需求,精准捕捉用户在模糊指令中的真实意图,提供更准确、个性化的响应;
在知识覆盖范围和深度上,Step-2不仅能够处理常见领域知识,还能深入理解和回答在特定领域或边缘分布中的复杂问题;
在生成高质量、有创意的文字内容的同时,Step-2具备出色的细节控制能力,能够根据用户的指令对文本进行精确地调整和优化。比如在创作古诗词时,对字数、格律、押韵、意境都可以做到精准把握。
研发阶段,阶跃星辰对算法架构的创新成为Step-2的制胜法宝。
目前,训练MoE模型主要有两种方式——一是基于已有模型通过upcycle(向上复用)开始训练,二是从头开始训练。前者对算力的需求低、训练效率高,但上限低,如基于拷贝复制得到的MoE模型容易造成专家同质化严重;后者训练难度高,但能获得更高的模型上限。
阶跃星辰选择了第二条,也是一条更难的路。
在设计Step-2 MoE架构时,该公司团队完全自主研发、从头开始训练模型,通过部分专家共享参数、异构化专家设计等方式创新MoE架构设计,让Step-2中的每个“专家模型”都得到充分训练,Step-2不仅总参数量达到了万亿级别,每次训练或推理所激活的参数量也超过了市面上的大部分Dense模型。
相比于Step-1千亿参数大语言模型,Step-2的综合能力提升了近50%。目前,Step-2已接入阶跃星辰旗下效率工具“跃问”。开发者可以在阶跃星辰开放平台,通过API接入使用 Step-2。
03.“最低调的学生”跑出高分,国产大模型未来可期
阶跃星辰成立于2023年4月,但在2024年3月才带着Step系列通用大模型正式面对公众。它就像是班级里那个最低调的学生,平日里埋头苦学,在考试的时候凭高分一鸣惊人。
目前,阶跃星辰已对外发布Step系列通用大模型矩阵,覆盖从千亿参数到万亿参数,从语言到多模态,从理解到生成的全面能力。
模型更新迭代的同时,产品应用也没落下。今年9月,在多模态大模型Step-1.5V的支持下,跃问App上线“拍照问”,不仅能识别图片中的物体并翻译成英文,还能帮助健身人士饭前算算卡路里。由于该功能实在火爆,网络还有跃问10月前20天投流1500万的传言,但后续被辟谣。
目前,在全球AI赛场上,国产大模型仍然屈指可数,中国AI独角兽们还有很多隐忧未解,阶跃星辰的技术路径或许可以为初创公司们提供一个参考样本。
本文来自微信公众号 “智东西”(ID:zhidxcom),作者:依婷,36氪经授权发布。