

NumPro团队 投稿
量子位 | 公众号 QbitAI
用看漫画的方式,大幅提升视频大模型时序定位能力!

方法名为NumPro,无需训练,通过数字视觉提示就能增强。
就像漫画中用编号的画格引导读者按顺序理解故事,将视觉内容与清晰的时间线联系起来一样。
NumPro通过在视频帧上添加独特的数字标识符,将视频时序定位转化为直观的“翻阅漫画”式过程,使Vid-LLMs能够轻松“读取”事件时间线,准确关联视觉内容与相应的时序信息。
实验中,NumPro显著提升了视频时序定位能力,在多个基准上超越此前SOTA,而且还能保持对模型通用视频理解能力影响较小。
这项工作由来自东南大学、马克斯·普朗克信息学研究所、腾讯微信团队、加州大学伯克利分校的研究人员共同完成。

NumPro方法核心创新
视频大语言模型(Vid-LLMs)在视频内容理解问答对话方面已取得显著进展,但在精确的时序定位任务(Video Temporal Grounding, VTG)上仍面临挑战。
例如,在实际应用中,识别视频中事件的发生时刻,如定位厨师添加调料的精确时间,对于现有模型来说颇具难度,这一挑战阻碍了视频理解技术在众多领域的深入应用。
传统方法在增强模型的VTG能力时,往往需要大量的重新训练或复杂的模型适配,灵活性和可迁移性受限。
NumPro是如何实现的呢?
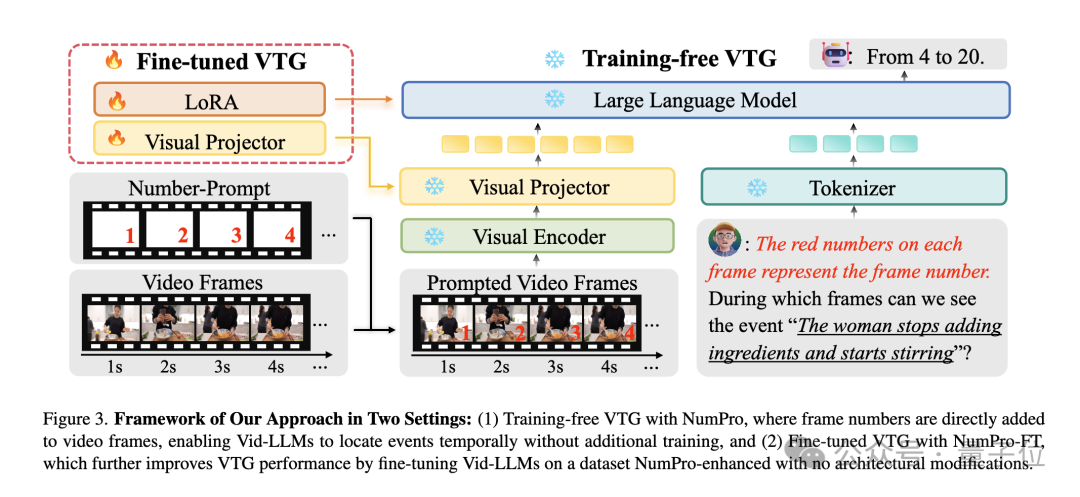
无需训练设置(Training-Free):
在无训练设置下,NumPro直接为每个视频帧标记对应的帧号。
借助Vid-LLMs内置的光学字符识别(OCR)能力,模型能够通过与视觉内容相关联的帧号“读取”时间线。
为明确添加数字的目的,在每个事件查询前添加简单指令,告知模型帧号的含义。如此,Vid-LLMs可直接将帧号与语言查询链接,准确识别帧级边界。
微调优化设置(Fine-tuning Setting):
为进一步提升性能,NumPro-FT在经过了NumPro增强数据集上对Vid-LLMs进行微调。
此过程将帧号与训练数据中的时间跨度对齐,将时序定位能力嵌入模型的学习表示中。
微调时,冻结视觉编码器,仅对视觉投影仪和大语言模型(LLM)组件进行优化,并采用低秩适应(LoRA)技术调整LLM,有效减少参数数量和训练开销。
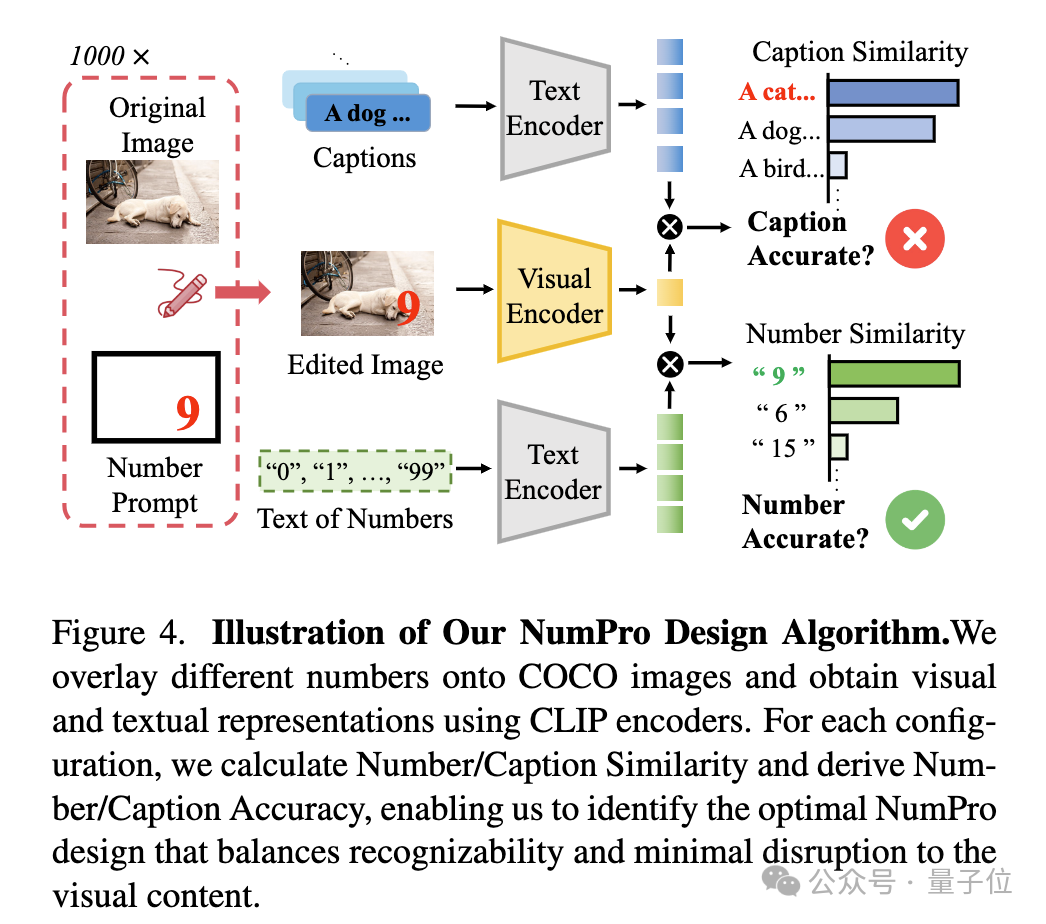
为确保NumPro的有效性,研究团队从字体大小、颜色和位置三个关键因素对其进行精心设计优化。
通过基于CLIP的实验,使用Number Accuracy和Caption Accuracy两个指标平衡数字的可识别性和对视觉内容的干扰。
最终确定了字体大小为40、颜色为红色、位置在右下角的最优设计,该设计能最大程度发挥Vid-LLMs的OCR和视觉语言对齐能力,实现精准的视频时序定位。
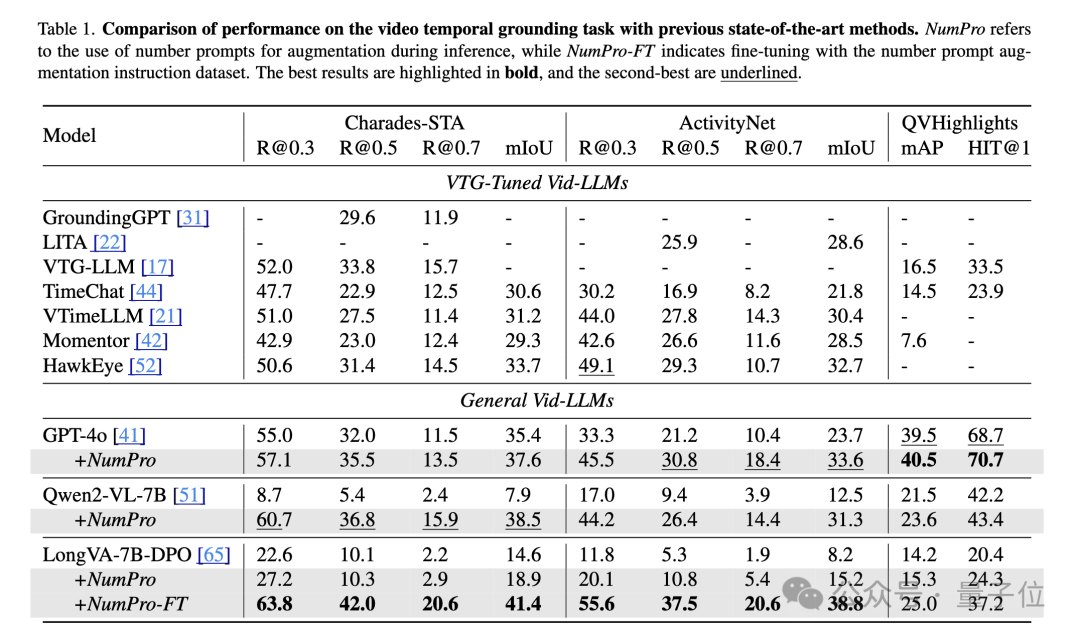
实验成果显著
在标准VTG基准测试中,NumPro表现卓越。
在Moment Retrieval任务中,无需训练的NumPro使Vid-LLMs性能接近或超越以往最优水平。
而经过NumPro-FT微调后,LongVA-7B-DPO在Charades-STA和ActivityNet数据集上的多个指标上均大幅超越现有SOTA,展现出NumPro在提升模型时序定位能力方面的巨大潜力。
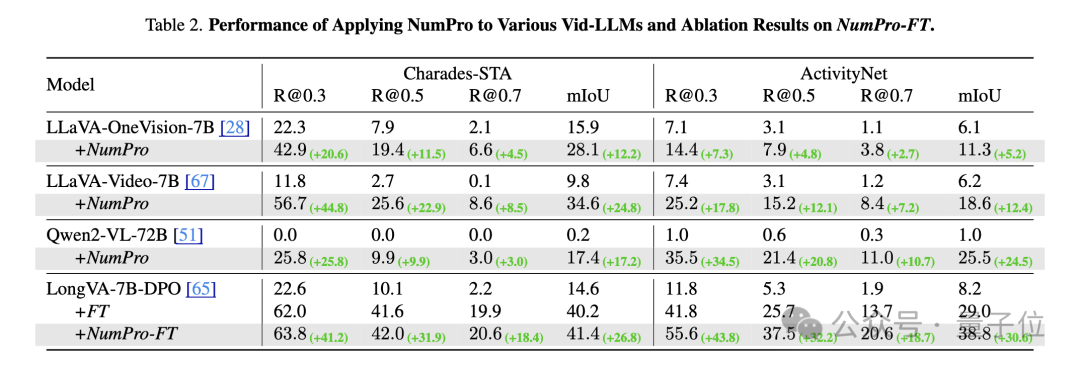
NumPro不仅在领先模型上效果显著,对多种Vid-LLMs也具有广泛的适用性。
应用于不同模型如LLaVA-Video-7B、LLaVA-OneVision-7B和Qwen2-VL-72B等,均带来了显著的性能提升。此外,在与微调结合时,NumPro-FT始终优于传统微调方法,尤其在较长视频数据集上表现出色。
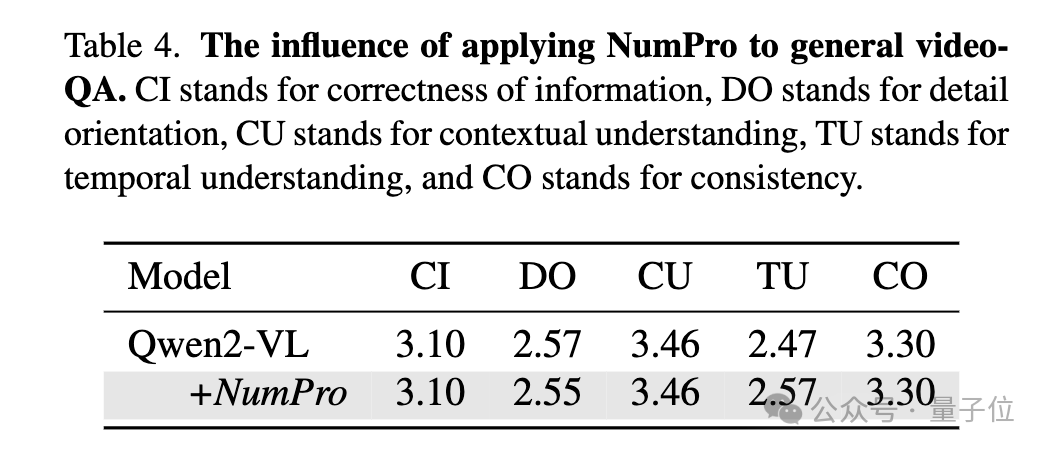
将NumPro集成到通用视频问答任务(如VideoInstruct基准测试)中,发现其对一般理解指标影响极小,在保持强大通用视频理解能力的同时,显著提升了视频时序定位能力。
论文连接:https://arxiv.org/pdf/2411.10332
代码仓库:https://github.com/yongliang-wu/NumPro