


美国国家工程院外籍院士沈向洋(图片来源:IDEA)
11月22日举行的2024年IDEA大会上,IDEA研究院创院理事长、美国国家工程院外籍院士沈向洋以“从技术突破到产业融合”为主题发表演讲,其对人工智能“三件套”(算力、算法、数据)的最新思考。
沈向洋指出,在技术大爆发时期开展创新,对技术的深度理解尤为重要。他认为,从算力来看,未来十年 AI 的发展可能需要增长 100 万倍的算力,远超摩尔定律预言的100倍增长,而英伟达成为了 AI 行业最了不起、最成功的一家公司。
根据EPOCH AI的数据,每年最新的大模型对算力的需求都在以惊人的速度增长,年均增长率超过四倍(400%)。截至目前,全球已经“烧掉”了超过1000万张GPU算力卡。
“英伟达硬生生把自己从自己从做硬件、芯片的乙方变成了甲方,今天能拿得到英伟达的卡就可以说是成功了一半。”沈向洋称,“讲(GPU)卡伤感情,没卡没感情。”
沈向洋现场透露,明天黄仁勋会到香港科技大学接受荣誉博士学位的授予,而他准备现在和黄仁勋讨论一些关于技术、领导力和创业的故事,特别是在针对算力发展的问题,探讨未来十年还会不会像过去十年那样能够达到100万倍的增长。
会后,沈向洋还向钛媒体App透露,Scaling Law(尺度定律)放缓的原因是GPT-5还没发布,背后主要与数据相关。
据悉,粤港澳大湾区数字经济研究院(International Digital Economy Academy,简称“IDEA研究院”)于2020年由微软公司原全球执行副总裁、美国国家工程院外籍院士沈向洋创建,是一家面向 AI 和数字经济产业和前沿科技的国际化创新型研究机构。
IDEA研究院致力于 AI 和数字经济领域前沿研究与产业落地。目前该院包括低空经济研究中心、计算机视觉与机器人研究中心、AI金融与深度学习研究中心、基础软件中心、AI安全普惠系统研究中心等。
此次,IDEA发布视觉、具身智能、合成数据、AI for Science、AI for Coding、低空经济等多个领域的新技术和新模型的前沿研究与产业落地成果,实现 AI 从技术突破到产业融合。
- 视觉大模型:IDEA团队本次大会发布了该系列最新的DINO-X通用视觉大模型,拥有真正的物体级别理解能力,实现开放世界(Open-world)目标检测,无需用户提示,直接检测万物。在零样本评估设置中,DINO-X Pro在业界公认的LVIS-minival数据集上取得了59.7%的AP,在LVIS-val数据集上,DINO-X Pro也表现亮眼,取得了52.4%的AP。具体到LVIS-minival数据集上的各个长尾类别评估中,DINO-X Pro在稀有类别上取得了63.3%的AP(比Grounding DINO 1.5 Pro还要高出7.2%),在常见类别上取得了61.7%的AP,在频繁类别上取得了57.5%的AP。
- 行业平台架构:IDEA团队还推出行业平台架构,通过一个大模型基座,结合通用识别技术结合,让模型不需重新训练,就可边用边学,支撑多种多样的B端应用需求。
- 具身智能:IDEA研究院此次便一连宣布三个合作:与腾讯合作,在深圳福田区、河套深港科技创新合作区落地建设福田实验室,聚焦人居环境具身智能技术;与美团合作,探索无人机视觉智能技术;与比亚迪合作,拓展工业化机器人智能应用。
- 合成数据:IDEA团队自研了语境图谱技术,解决过往文本数据合成方案的多样性匮乏等问题。该技术为合成数据引入“指导手册”,以图谱为纲,指导用于合成的语境采样。实验结果显示,IDEA团队的方案能持续为大模型带来能力提升,表现超过目前的最佳实践(SOTA);从token消耗来看,平均节约成本85.7%。目前,该技术内测平台已开放,通过API提供服务。
- AI for Science:在预测方面,IDEA研发了多个化学领域专家大模型,分子属性预测和化学反应预测能力均处业界领先水平;在数据方面,IDEA开发了化学文献多模态大模型,联合晶泰科技发布专利数据挖掘平台PatSight,将药物领域的专利化合物数据挖掘时间,从数周缩短至1小时。
- AI for Coding(编程语言):IDEA研究院的MoonBit团队展示了其开发平台强大的AI for coding体验。MoonBit是专为云计算与边缘计算设计的AI云原生编程语言及工具链,已具备完备的多后端支持和跨平台能力,可在硬件上直接运行,支持RISC-V。MoonBit的开源开发平台,将于12月正式开放。
- 低空经济:IDEA推出低空管理与服务操作系统OpenSILAS 1.0 Alpha版,还携手17家产业伙伴发起OpenSILAS创新联合体,以及《低空经济白皮书3.0》低空安全体系的发布等。
此外,IDEA还展示包括学术大模型和AI科研神器ReadPaper、营销创作大模型,以及面向经济与金融领域的经济大模型、运筹决策大模型、投资大模型等多款新 AI 技术与产品。
沈向洋表示,在过去所有广受欢迎的编程语言中,还没有一个是由中国开发者创造的,而如今,AI 时代也必将催生新的编程范式,中国开发者将会起到关键作用。
“ChatGPT 展示了一种新的可能:当技术突破达到一定程度,可以跳过传统的产品市场匹配(PMF)过程,直接实现技术市场匹配(TMF)。”沈向洋表示,如果 GPT-5 问世,按照其估计,可能需要 200T(200万亿)规模的数据。
沈向洋强调,AI 正在改变科研方式。从“确定方向”(ARCH)到“选择课题”(Search),再到“深入研究”(Research),每个环节都将被重塑。今天o1不仅可以做数据、做编程,还可以做物理、做化学等。
“我觉得接下来这几年,算法沿着SRL(强化学习)这条道路走下去,一定会有令人惊艳的全新突破。”沈向洋表示。
(本文首发于钛媒体App,作者|林志佳,编辑|胡润峰)
以下是沈向洋演讲的主要内容,钛媒体AGI编辑精心整理了其中精彩部分:
今天是 IDEA 研究院在深圳举办的第四届 IDEA 大会。
回顾发展历程,三年前的第一届大会上,IDEA 首次向公众展示了研究院的工作成果。在第二届大会上,我们邀请了李泽湘教授、徐扬生教授、高文教授等学界翘楚进行深入对话。大家开玩笑讲地我们四个人叫做深圳F4。
值得一提的是,这些学者都是我 90 年代初赴美留学时最早结识的中国学者。三十年后我们能在深圳重聚,恰恰印证了深圳作为创新创业热土的独特魅力。
经过四年发展,IDEA 研究院已发展成拥有 7 个研究中心、约 450 名员工的科研机构。我们选择这些员工,双向选择的过程中我们强调这样的理念,“科学家头脑、企业家素质、创业者精神”。来到深圳、来到福田、来到IDEA都是想干一番事业。
过去几年,人工智能的蓬勃发展让整个行业充满憧憬和期待。在人工智能发展进程中,“算力、算法、数据”这三件套始终是核心要素。接下来,我将从这三个方面,详细分享自己的观察和思考。
首先从算力说起。
作为计算机领域的从业者,我们一直见证着整个计算行业过去40、50年来算力的不断提升。早期有著名的“摩尔定律”,英特尔提出每 18 个月算力增长一倍。
但在过去十几年,随着人工智能,特别是深度学习的发展,对算力的需求呈现出前所未有的增长态势。
根据 EPOCH AI 的数据,每年最新的大模型对算力的需求都在以惊人的速度增长,年均增长率超过四倍。
这个数字意味着什么?如果按照这个增长速度,十年间算力需求的增长将达到惊人的 100 万倍。相比之下,传统的摩尔定律下 18 个月翻一倍的增长,十年也不过是 100 倍的增长。
算力是关键,算力就是生产力。为什么这样讲?过去十几年可以毫不夸张的讲,IT行业、人工智能行业最了不起的一家公司、最成功的一家公司,不管从哪个角度看就是NVIDIA英伟达。
英伟达已经从一家单纯的硬件芯片供应商,转变为整个行业的核心支柱。现在行业里流传着这样一句话:英伟达硬生生把自己从做硬件、芯片的乙方公司做成了甲方,而今天拿得到英伟达的卡,那你就成功了一半。
让我们看看具体的数据:2023 年英伟达最新产品 H100 的出货量持续攀升,各大公司争相采购。包括马斯克最近就部署了一个拥有 10 万张 H100 卡的大规模集群。到 2024 年为止,微软、谷歌、亚马逊等科技巨头都在大量采购 H100 芯片。
为什么需要如此庞大的算力?这与大模型的发展密不可分。
Scaling Law告诉我们,大模型不仅参数量巨大(从百亿到千亿,再到万亿参数),而且训练所需的数据量也在不断增长。更关键的是,要提升模型性能,对算力的需求会随参数量呈平方关系增长。这就解释了为什么过去十年英伟达的市值能够增长 300 倍,也说明了“算力就是生产力”这一论断的深刻含义。
一旦这么大的参数以后,要能训练这样的模型,数据量也要增长,某种意义上来讲,要把性能提升,对算力的需求呈跟参数的平方关系,这对整个算力的需求是非常庞大。
过去这一年来我经常讲的一句话,“讲卡伤感情,没卡没感情”。

前不久我在上海演讲的时候台下有位大学校长,各位老师要对校长表示同情,校长也不好当。老师说你给我100张卡,我可以做些科研,给你100张卡,校长几千万就没有了。
在人才招聘方面,算力资源已经成为一个重要指标。有些企业会以“千卡人才”、“百卡人才”来形容人才规模,真正顶尖的甚至被称为“万卡人才”。IDEA 研究院已经拥有了千张卡的算力储备,在深圳算得上是“小土豪”级别的规模。
这也解释了为什么过去十年英伟达的市值涨了300倍,这是不可想象的事情,
这种算力需求的变革被业界称为从“摩尔定律”到“黄氏定律”的转变。黄氏定律不仅体现在硬件算力的增长上,更重要的是反映了模型训练对算力需求的指数级增长。未来十年的算力需求是否会继续保持如此惊人的增长速度,这个问题值得我们持续关注和思考。
之前我在大湾区论坛也是提到过去十年算力的增长100万倍,有一篇文章写的不准确,他说沈向洋讲,未来十年算力的需求会有100万倍的增长。其实我并没有这样讲,我也不是看得很清楚,接下来十年的算力需求是不是会增长100万倍。
明天中午我在香港有机会请教黄仁勋博士,黄仁勋博士到香港科技大学接受荣誉博士学位,之后会和我做一个对谈,讲技术、领导力、创业的故事。我明天有机会想请教他一下未来十年的发展会不会有100万倍的增长。
其次是算法。

在算法方面,自 2017 年 Transformer 架构问世以来,人工智能、深度学习和大模型的发展基本上都是沿着这个方向,通过堆数据和算力来推进。但在 GPT-4 之后,我们看到了算法范式的新突破。特别是 OpenAI 推出的新技术,包括多模态的 GPT-4V 以及最新的 o1 推理学习能力,展现了算法创新的新方向。
令人欣喜的是,近几个月来,国内也有一些公司,包括初创企业在 o1 这个方向上取得了显著进展。
这里我想详细介绍一下算法突破的思路。在 o1 出现之前,大家谈论的都是 GPT 系列,所有的工作都集中在预训练上,核心任务就是预测“下一个token”。其中很重要的技术背景是对所有数据进行高效压缩,使模型能够快速给出答案,实现“一问即答”。
而现在的范式变革引入了强化学习(Reinforcement Learning)的理念,模型具备了自我改善的能力。这种新方法的特点在于,它更接近人类的思考方式。不同于之前的快速思考模式,现在的模型在给出答案时会经历后训练、后推理的过程。这就像学生在解数学题时会先打草稿,验证一条路径是否正确,如果不对就回退尝试另一条路径。
虽然强化学习本身并不是一个新概念——比如几年前 AlphaGo 就使用强化学习打败了围棋世界冠军——但今天的创新在于它的通用性。过去的强化学习系统往往只能解决单一问题,而像 o1 这样的新系统可以同时处理数据分析、编程、物理、化学等多个领域的问题。我认为,在未来几年,沿着 Self-Reinforcement Learning (SRL) 这条道路,我们将看到更多令人惊艳的突破,期待 IDEA 研究院和国内的研究人员能在这个方向上有更多的思考和创新。
最后是数据。
在讨论数据之前,我已经提到,大模型的蓬勃发展不仅依赖于参数规模的增长,还需要海量数据的支持。让我和大家分享一些关于数据规模的具体数据。

三年前 GPT-3 发布时,使用了 2Trillion(2万亿)的 token 数据。到了 GPT-4 时代,模型训练使用的数据量增加到了 12T,在不断训练过程中可能达到了 20T。这个规模大致相当于目前互联网上可获取的优质数据总量。而未来如果 GPT-5 问世,按照我的估计,可能需要 200T 规模的数据。
但问题在于,互联网上已经很难找到如此庞大的优质数据。这就引出了一个新的研究方向:合成数据。
为了让大家对这些数据规模有更直观的认识,我举几个例子:1 万亿 token 的数据量大约相当于 500 万本书,或 20 万张高清照片,或 500 万篇论文。从人类历史的角度来看,至今为止创造的所有书籍大约包含 21 亿 token,微博上有 38 亿 token,而 Facebook 上约有 140T 的数据。不过社交媒体上的数据质量普遍不够高,真正有价值的内容相对有限。
从个人维度来看,一个人读完大学,真正学到的知识量大约是 0.00018T,相当于 1000 本书的内容。如果觉得自己还没读到这个量级,也许现在开始该多读些书了。
有趣的是,ChatGPT 等 AI 模型的训练数据主要来自互联网。回顾互联网发展的 40 年,人们热衷于在网上分享信息,现在看来,似乎是在为 GPT 的训练做准备。AI 之所以如此智能,很大程度上得益于我们贡献的数据。这其中还有一个值得注意的现象:无论训练哪种语言的 AI 模型,底层的高质量数据主要是英文的。这意味着在 AI 时代,英语的重要性可能会进一步加强,就像互联网时代一样。
既然网上的数据已接近极限,AI 的进一步发展就需要依靠合成数据,这可能催生新的百亿美元级创业机会。
与 GPT 系列主要使用互联网文本数据不同,新一代模型(如 o1)需要更强的逻辑性,这些数据在网上往往找不到。比如在编程领域,我们需要知道具体的步骤是如何一步步完成的。在 IDEA 研究院,在郭院长的带领下,我们开展了高质量训练数据的项目,为大模型持续提供新的“养分”。
我们的合成数据方法并非盲目生成,而是建立在严谨的方法论基础上。我们首先建立语境图谱,在此基础上进行数据合成。这些合成数据经过大模型预训练后,已经展现出很好的效果。
除此之外,我们还在探索另一个维度的问题:私域数据安全孤岛。由于数据安全考虑,许多私域数据无法直接共享使用。为此,我们开发了 IDEA Data Maker,将这两个方面结合起来,通过语境图谱生成新的语料,解决过往文本数据合成方案的多样性匮乏等问题。该技术为合成数据引入“指导手册”,以图谱为纲,指导用于合成的语境采样。实验结果显示,IDEA 团队的方案能持续为大模型带来能力提升,表现超过目前的最佳实践(SOTA)模型;从 token 消耗来看,平均节约成本 85.7%。目前,该技术内测平台已开放,通过 API 提供服务。
在讨论了 AI “三件套”之后,我想分享 IDEA 研究院近一年来的思考和实践。特别是大模型蓬勃发展给我们带来的机遇。
讲大模型之前我讲一下最近的学习体会,ChatGPT出来了以后令大家非常震撼。ChatGPT这个产品出来,本来只是几个技术的演示,它出来以后两个月的时间全球1亿用户,成为了不起的现象。
这种现象打破了我们对产品发展的传统认知。在互联网时代,我们常说 PMF(Product-Market Fit,产品市场匹配)。对这个概念的理解,我多次请教过美团的王慧文,在清华的一堂课上,他专门讲解了 PMF 的内涵。
但 ChatGPT 的成功告诉我们,它实际上跳过了 PMF 的过程,直接实现了TMF(Technology-Market Fit,技术市场匹配)。当技术发展到一定程度,就可能实现这样的跨越式突破。
在 IDEA,我们天天在追求一些极致的技术,也在思考:如果有技术出来,是否可以一步到位?这当然是我们的期望,我们一直在朝这个方向努力。
顺着 TMF 的思路,我想讲一个最近我们特别关注的方向:计算机编程语言。作为一个学习计算机的人,我自己就编写过十几种不同的编程语言,在不同的阶段做不同的项目时都会用到它们。
在这里我想提出一个重要观点:纵观全球,有那么多的编程语言,包括小语言、大语言、中型语言,但基本上没有一个被广泛使用的语言是由中国人发明、中国人创造的。这种现象是有机会改变的。
让我给大家举几个例子,说明什么是现象级的语言。
在过去七八十年的计算机科学发展历程中,出现过的现象级语言不超过十个。这里的“现象级”是指至少有几百万、上千万用户在使用这个语言编程。比如早期的 Fortran,当时是和 IBM 大型机绑定的,做三角计算都要用 Fortran 语言。70 年代出现的 C 语言,是与 Unix 操作系统紧密相连的,甚至可以说 Unix 系统就是用 C 语言构建的。到了 90 年代互联网兴起时,我师兄开发的 Java 语言被大量程序员采用,主要用于开发 Web 服务器。而在过去十几年,Python 因为在科学计算方面的便利性,特别是在云计算平台上的广泛应用,成为主流语言。如果你问问自己的孩子在学什么编程语言,大概率会是 Python。
那么,在今天的大模型时代,会不会出现新的现象级语言?这个问题不是只有我一个人在思考。比如,GitHub Copilot 的创始人 Alex Graveley 就指出,AI 编程还没有形成新的编程语言范式。编程语言是最根本的技术创新方向之一。
有了语言之后,就需要探索大模型的技术创新方向。在大模型能力已经达到新高度的今天,一个关键问题是:我们如何将这种能力转化为实际应用?在哪些场景中可以发挥其最大价值?
在所有的应用方向中,我特别要强调 AI For Science(科学智能)的重要性。可以说,在当前阶段,很难想象有什么比 AI For Science 更重要的方向。如果我们要做人工智能研究,一方面要全力推动大模型技术的落地,另一方面也要关注它在科学研究中的应用。
这让我想起二十多年前在微软亚洲研究院做过一个关于如何做科研、如何做学问的报告。我把科研工作分成了三个不同的层次:ARCH(确定方向)、Search(选择课题)、Research(深入研究,一而再再而三地探索)。现在,我们希望 IDEA 的工作能为中国的科研人员、年轻学生在做科研时提供更好的支持。
事实上,人工智能的发展正在对社会产生深远的影响。这个问题太重要了,需要我们认真思考。我们今天要讨论的是 AI 治理问题,包括它对民众的冲击、对公司的冲击、对监管的冲击、对社会发展的冲击。

人工智能的影响究竟是如何发生的?八年前,人们还在讨论社交媒体的影响,而今天我们必须要讨论人工智能的影响。
过去十几年的发展令人震惊:人类引以为傲的能力正在一个个被 AI 超越。下象棋、下围棋就不必多说,现在AI在阅读理解、图像识别和检测等领域的能力都已经逐步超越人类。
更令人震撼的是,这些能力的提升已经不是单点突破,而是通用人工智能整体能力的提升,这使得人工智能对社会的影响变得异常深远。
现在,全球范围内都在讨论 AI 治理问题。我有幸在今年上海人工智能大会上与我的导师瑞迪教授、布卢姆教授和姚期智教授一起讨论这个议题。
从社会发展的角度来看,我们习惯用 GDP 来衡量发展水平。但 GDP 这个概念其实是很新的。在农业社会之前,根本不存在 GDP 增长的概念,因为人们连温饱都难以解决。农业社会发展后,人们有了剩余产能,但 GDP 年均增长仍然只有 0.1% 至 0.2%。到了工业社会,这个数字提升到 1% 至 2%。信息社会的 GDP 年均增长达到了3%、4%,这里说的都是全球的大致数字。
那么,在接下来AI社会的发展,会发生什么?一些经济学家预测,随着人工智能数量超过人类数量,机器人数量急剧增加,生产效率将获得巨大提升。在这样的 AI 世界中,GDP 年均增长可能达到十几个百分点。
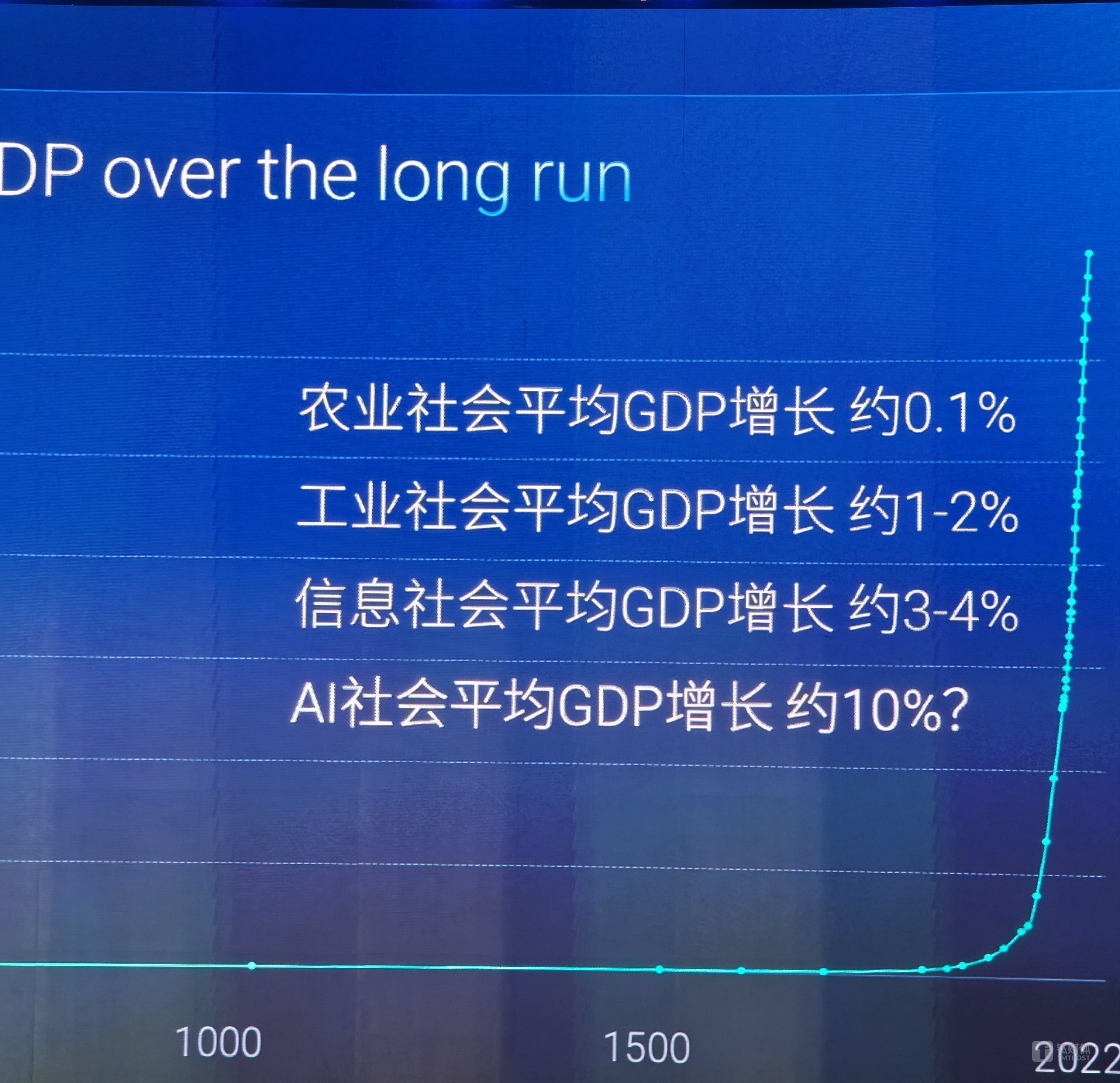
这样的增长给社会带来的问题是什么?我想问的一句话是AI的发展,从经济最大的增长能不能转化到人类的最大福祉?这是为什么在座的,在IDEA研究院从事技术研发的同事,产业落地这些同事在人工智能发展的道路上是必须要去思考的问题。
谢谢大家!期待明年再见。
