

STA团队 投稿
量子位 | 公众号 QbitAI
如果你面前有两个AI助手:一个能力超强却总爱“离经叛道”,另一个规规矩矩却经常“答非所问”,你会怎么选?
这正是当前大模型控制面临的两难困境:要么模型聪明却难以约束,要么守规矩却缺乏实用性。但我们真正追求的,并不是在“聪明但难控”与“听话但愚钝”之间二选一,而是打造既强又好的AI助手——既具备强大的智能能力,又能始终按照人类意图行事。
ACL 2025中选论文中,来自浙江大学与腾讯的联合团队提出了新思路:Steering Target Atoms(STA),尝试为大模型注入“行为定向剂”,助力对模型行为的精准调控,为构建既聪明又听话的AI打下基础。

该方法通过“原子级”粒度对大模型进行行为编辑干预,实现了更鲁棒、更安全的生成控制。
在Gemma和LLaMA系列模型上的实验表明,STA方法能够有效抑制越狱攻击带来的违规输出,同时不削弱模型在正常问题回答中的高质量智能表现。

方法&实验结果大模型行为控制的挑战与突破
在参数训练完成后,很多应用场景会需要在推理阶段调整模型的特定行为,例如让模型拒绝用户的恶意请求。
然而,模型的“安全防御”能力往往和它的“通用智能”能力紧密耦合:为了让模型学会拒绝有害输入,可能会不小心削弱它对正常问题的应对能力。
目前最常用的解决方案是通过精心设计Prompt,在输入端“兜底”以控制输出。但这种方式也存在明显弱点:Prompt 容易被越狱攻击绕过,一旦攻击者找到绕过思路,模型就可能产生不安全或偏离预期的回答。
为了解决这一难题,研究团队提出了Steering Target Atoms(STA)方法。STA不再仅仅在输入或输出层做文章,而是深入到模型内部——分析各层神经元的激活模式,找到哪些“原子级”神经元与有害行为高度关联,哪些又对应正常目标输出。
基于此,STA会对这些关键神经元的激活频率和幅度进行有针对性的干预:抑制与“越狱”或输出违规内容相关的神经元,同时保留或增强与正确回应对应的神经元活性。
简单来说,它不仅让模型“守规矩”,还不必以牺牲通用性能为代价。
STA方法
目前的Steering方法通常借助于稀疏编码器(Sparse Autoencoders,SAE)将耦合的目标方向分解到更高维度的空间以便解耦到单语义方向。
然而这些尝试通常在一些简单的选择题任务上尝试(比如动词的时态变化、实体识别),本文将其扩展到开放生成式任务上。
具体来说,STA方法分别追踪一个query的正向回复和负向回复在前向传播中激活特定神经元的频率和幅度;用正向频率(幅度)减去负向频率(幅度)得到表示目标方向的频率(幅度)。最后根据目标方向频率(幅度)的阈值筛选出目标方向的原子。
实验设置
在后面的实验中研究人员通过操纵目标原子的方向和幅度调控目标行为。在Gemma-2-9B-pt、Gemma-2-9B-it和Llama-3.1-8B做了大量实验,评估STA方法在大模型安全防御场景的性能。
在比较的基线方法中,Prompthand是手工设计的Prompt,Promptauto是自动生成的Prompt,CAA是一种不使用SAE的Steering策略,SAEAXBENCH是一种使用SAE的Steering策略。
主要实验结果
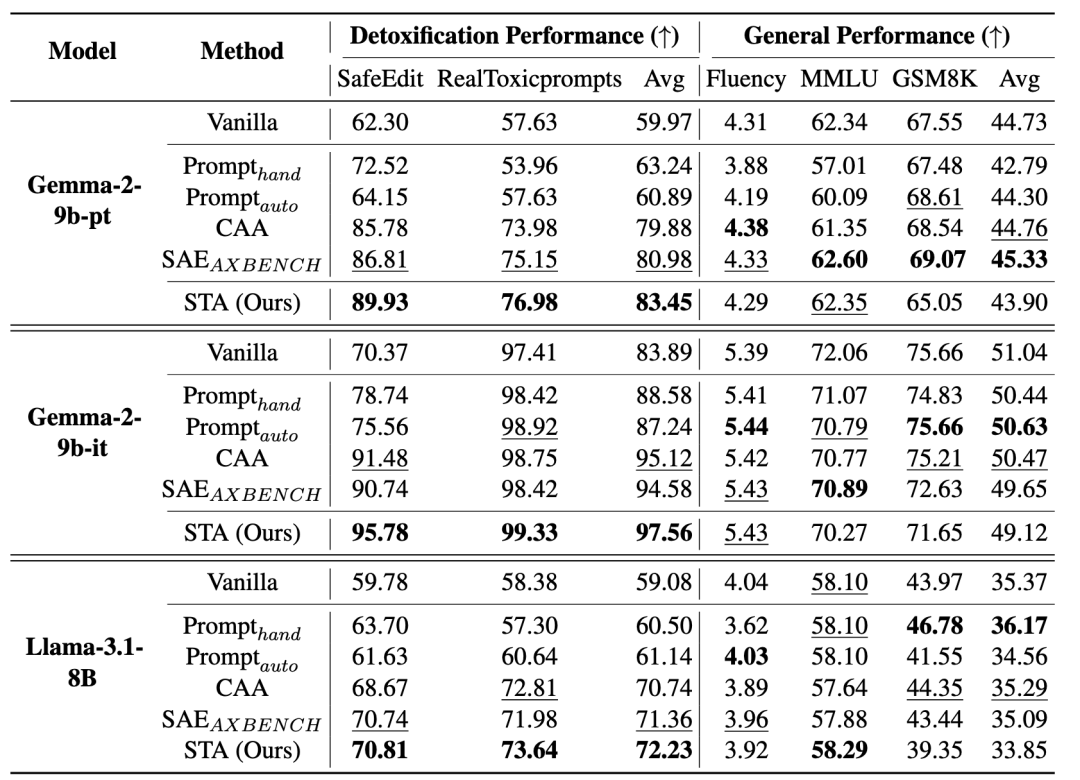
如上表所示,本文提出的方法可以适用到Gemma和Llama家族模型上;总体上来说STA取得了最好的祛毒效果,且几乎没有在通用能力上引入副作用。
Steering Vectors VS. Prompt Engineering
研究人员进一步分析了Steering Vectors技术和提示工程技术的对比。他们不能穷举出所有的Prompt然后确定最优的Prompt,也无法保证他们的Steering技术是最优的。
因此为了公平地对比Steering和Prompting策略,团队直接用CAA以及STA将Prompt直接转化成Steering向量进行对比。实验结果发现:
1.Steering面对越狱攻击时比Prompting更加鲁棒。
2.Steering可以调控的幅度比Prompting更大,粒度更细。
此外研究人员还将Steering策略用于DeepSeek-R1-Distill-Qwen-7B模型缓解Overthinking问题,实验结果如下图:

编辑干预千亿大模型Deepseek-R1的思考过程
研究人员在更大的模型DeepSeek-R1(671B)上也做了干预思考的实验。根据Deepseek-R1的MoE架构,他们选择干预MoE的专家。具体细节详见“Two Experts Are All You Need for Steering Thinking: Reinforcing Cognitive Effort in MoE Reasoning Models Without Additional Training”。
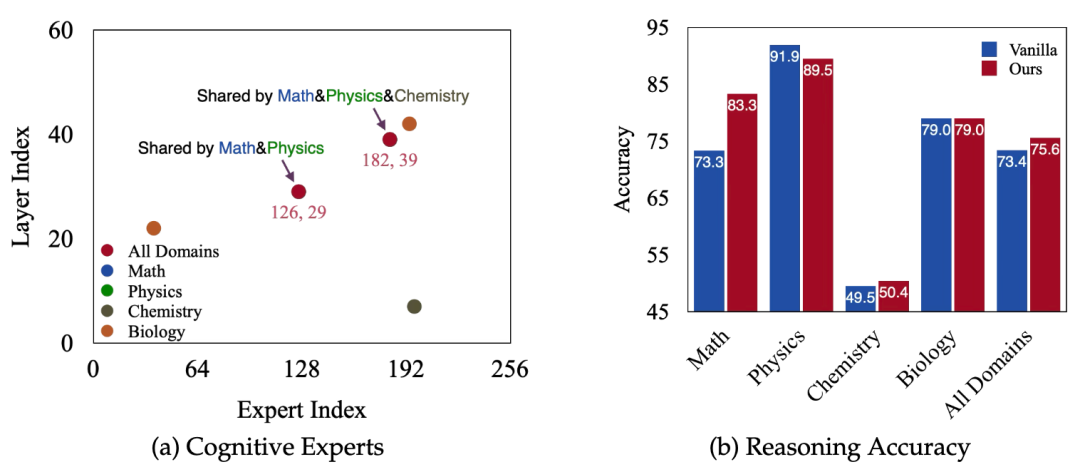
具体而言,研究人员通过nPMI指标识别出与“思考”密切相关的认知专家神经元,并对其权重进行放大干预。实验发现,在数学和物理等任务中,这些认知专家具有高度的一致性。
进一步地,对这些关键神经元进行干预后,模型的整体认知思考能力得到了提升,表现出更强的推理和理解能力。
总的来说Steering Vector这类技术基于对模型内部的理解来调控模型的行为,虽然没有Prompt方便,但是干预的效果更加鲁棒和精确。然而大模型是一个复杂系统,本文借助的SAE在一些场景下效果并不理想,反向调控也可能引入一些负面行为。
为推动社区在安全可控大模型方向的进一步探索,研究人员已经将部分干预方法开源,欢迎大家使用、探索。
论文地址:
https://arxiv.org/abs/2505.14681
代码地址:
https://github.com/zjunlp/steer-target-atoms
https://github.com/zjunlp/EasyEdit/blob/main/README_2.md
overthinking问题地址:
https://arxiv.org/abs/2412.21187
干预Deepseek-R1的思考过程:
https://arxiv.org/abs/2505.14681
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

点亮星标
科技前沿进展每日见