

DeepTheorem团队 投稿
量子位 | 公众号 QbitAI
12.1万道IMO级难度数学“特训题”,让AI学会像人类一样推导数学证明!
“特训”过后,模型定理证明性能大涨,7B模型性能比肩或超越现有的开源模型和Claude3.7等商业模型。
“特训题”为DeepTheorem,是首个基于自然语言的数学定理证明框架与数据集,由腾讯AI Lab与上海交大团队联合推出。

团队表示,定理证明是数学前沿的重要组成部分,但当前大语言模型(LLM)在数学推理,特别是通过强化学习(RL)进行训练时,往往需要可以自动验证的答案,导致大模型无法像数学家那样通过自然语言进行定理证明。
而当前研究者通常通过使用大模型生成Lean、Coq、Isabelle等形式语言,配合外部定理证明引擎进行定理证明,无法充分利用LLM在自然语言预训练过程中获得的能力。
为解决这一问题,DeepTheorem框架横空出世,包含了从数据、训练、测试到评估的完整四部分:
121K大规模、高难度、严格去污染的自然语言定理与o3-mini生成的配套证明过程
首个使用强化学习进行数学定理证明的方法
分别基于FIMO、HMMT、PutnamBench构建的三个自然语言定理证明测试集
涵盖结果监督与过程监督的全面评价指标
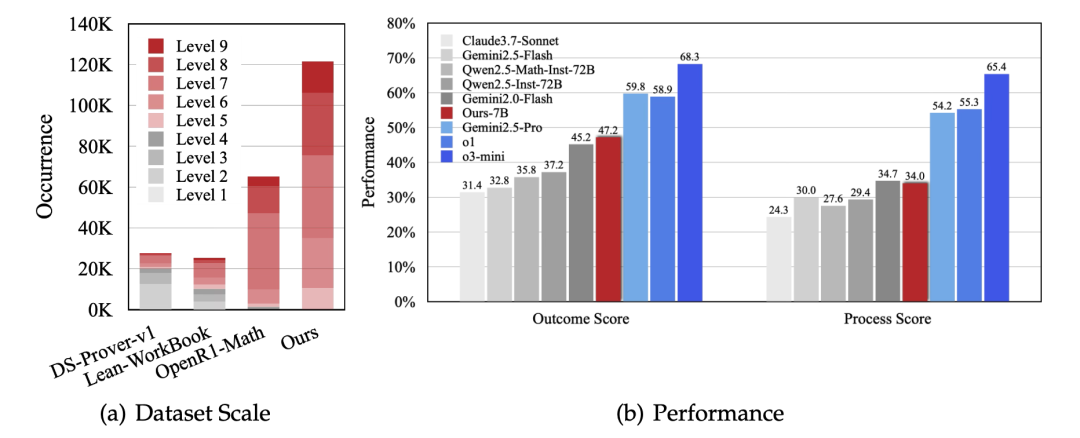
如下图(a)所示,DeepTheorem数据在规模和难度上均显著超越目前已有的公开定理数据集。
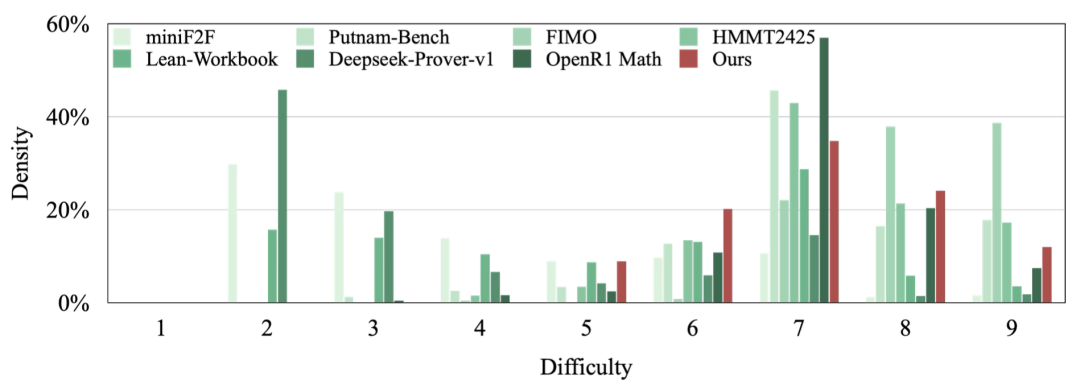
图(b)展示经过强化学习训练的DeepTheorem-7B模型性能,比肩或超越现有的开源模型和商业模型(Gemini2.0-flash, Qwen2.5-72B-Instruct, Claude3.7等),仅次于o1、o3以及Gemini2.5-pro强推理模型。
DeepTheorem-121K
1、规模与难度:专为“极限挑战”而生
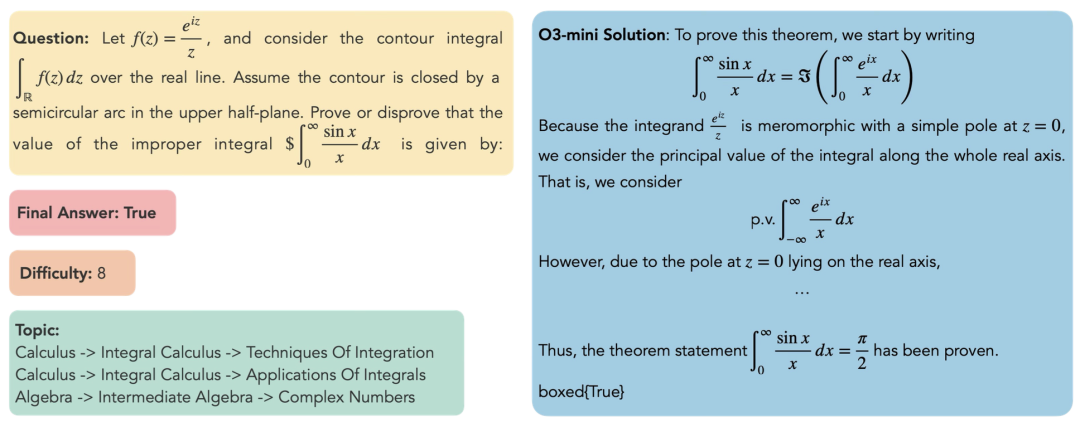
DeepTheorem训练集的显著特点是其大规模与高难度。其包含121K精心构造的数学定理,难度等级为5-9级,规模显著大于现有数学定理数据且难度更高,与FIMO等国际数学奥赛级别的测试集难度分布相似。
2、严格去污染:确保评估“纯净”
DeepTheorem训练集的构建过程堪称“匠心独运”,通过一个细致的五阶段流程构造:

来源分析与收集:分析现有数据来源,选择难题比例高的数据源。
数据去污染:使用嵌入相似性搜索和LLM-Judge来识别并消除与MATH、AIME、GPQA等14个通用数学和STEM基准以及miniF2F、PutnamBench、FIMO等四个数学定理证明基准的重叠,确保评估的完整性并防止数据泄露。
证明生成与质量控制:使用o3-mini生成定理证明过程,并使用GPT-4o对定理完整性进行评估,保留定理与证明过程完整的样本。
难度过滤:使用GPT-4o对定理进行难度评估,保留难度等级5或更高的定理。
单命题过滤:根据定理中的子命题个数进行筛选,保留仅含一个自命题的定理。
3、独特结构:兼顾SFT与RL
DeepTheorem训练集中的每条数据都包含丰富的信息,支持多种数学推理研究和应用:
问题:核心的数学定理陈述。
最终答案:定理的真值(真或假),这对于在可验证奖励强化学习(RLVR)中基于规则的奖励函数至关重要,是自动化评估和反馈的基础。
难度:数值难度标注,支持难度感知训练。
主题:分层主题分类,涵盖从初等代数到抽象代数、微积分的广泛数学主题。
o3-mini证明过程:由o3-mini模型生成的证明过程,对于监督微调和模型蒸馏等多种训练范式都具有巨大价值。
将RL-Zero引入数学定理证明
1、数据增强:定理可以被证明,也可以被证伪
为将可验证奖励强化学习(RLVR)引入自然语言数学定理证明,DeepTheorem通过自动化的方法来对每个原始定理进行扩展,衍生出多个可被证明或证伪的变体。

以定理“x>1”为例,若该定理成立,则变体一“x>0”也一定成立,而变体二“x<1”则一定不成立。通过这种方式,DeepTheorem仅基于定理本身(而不需要接触证明过程)使用大模型对训练集中的所有定理进行扩展,获得242K定理及变体。
2、二值奖励激发定理证明能力
在获得定理变体后,DeepTheorem使用基于GRPO的RLVR进行定理证明训练。对于训练集中的每一个定理,模型的任务是将其证明或证伪,并在最终答案中给出判断(证明或证伪)。
基于规则的奖励函数根据模型最终答案进行打分,若答案正确则得一分,若无法提取答案或答案错误则得0分。
DeepTheorem评估框架
1、DeepTheorem测试集
在经过对问题难度、污染程度、数据可用性等多方面因素的综合考虑后,作者们选择了两个现有的定理证明测试集FIMO与PutnamBench,并从当前污染较少的HMMT测试集中手工筛出了定理证明相关题目,构成三个自然语言定理证明测试集。
模仿对训练数据中的定理进行数据增强的方式,DeepTheorem的作者们对这三个测试集中的每个定理手工扩展出了多个变体,构成最终测试集:
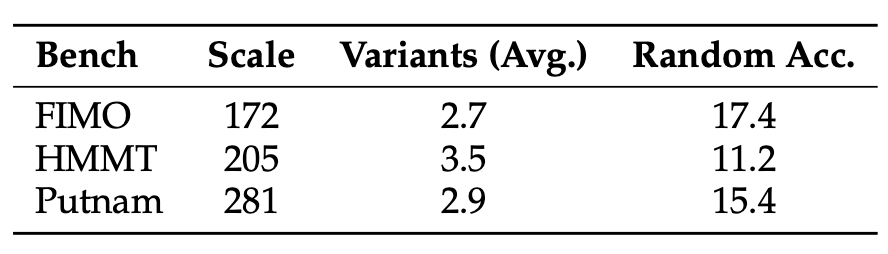
最终测试集中,平均每个定理包含约三个变体,三个测试集总变体数658个。
2、结果与过程评价指标
在DeepTheorem测试集上,模型性能由两部分评价指标构成:结果评价与过程评价。
结果评价的指标定义为:对每一个原始定理,若模型成功将其全部变体证明或证伪则得1分,否则得0分。基于此定义,我们可以对每个变体随机赋予“证明”或“证伪”的答案获得随机基线。此基线在三个测试集上的性能如上表Random Acc.列所示。
过程评价使用LLM-as-Judge,由GPT-4o从逻辑正确性、完整性、最终答案正确性以及过程清晰性四个维度对证明过程进行打分。
DeepTheorem模型性能达到SOTA
实验结果表明,在DeepTheorem数据集上使用RL-Zero基于Qwen2.5-7B训练的模型拥有同规模模型中的SOTA性能。
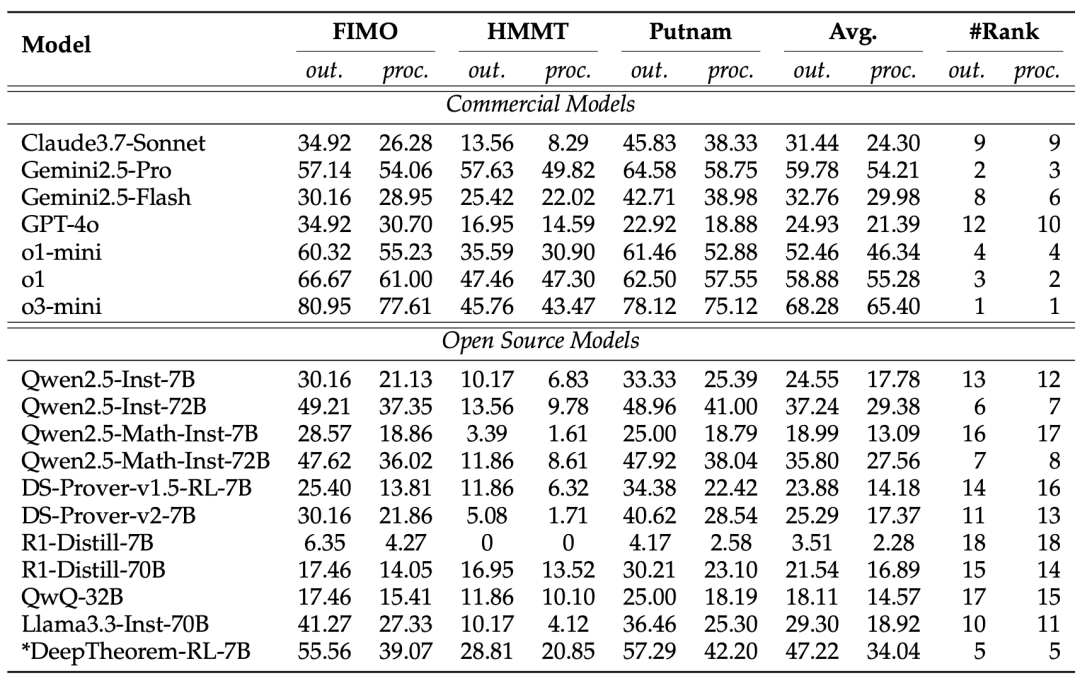
显著优于DeepSeek-Prover等参数量相近的现有定理证明模型以及Qwen2.5-Math-72B等更大的模型,甚至比肩Claude3.7-Sonnet等闭源模型,在所评测的18个模型中性能排名第五,仅次于o1系列、o3-mini以及Gemini 2.5 Pro。

以下为DeepTheorem-RL-7B在测试集上随机挑选的输出样本。模型在证明过程中展现出了清晰准确的逻辑性,且仅使用Latex,简洁易懂。

团队表示,DeepTheorem框架的发布,无疑为人工智能在数学推理领域的应用开辟了全新的思路,它不仅突破了使用形式语言进行定理证明的传统范式限制,更通过其大规模、高质量的训练数据提升了AI在前沿数学方面的卓越性能。
我们期待,在DeepTheorem的推动下,AI能够真正学会定理证明,从封闭的计算、简答题目走向更广阔的数学殿堂,最终迈向更强大、更具通用性、认知上更复杂的智能系统。
团队简介
本文通讯作者徐嘉豪, 腾讯AI Lab高级研究员,研究方向为推理大模型,在NIPS,ACL,EMNLP等国际顶级会议上发表多篇论文。
共同通讯作者涂兆鹏,腾讯混元数字人专家研究员,研究方向为深度学习和大模型,在国际顶级期刊和会议上发表学术论文一百余篇,多次担任ACL、EMNLP、ICLR等国际顶级会议领域主席。
共同通讯作者王瑞,上海交通大学副教授,研究方向为计算语言学。
第一作者为上海交通大学博士生张子殷。
论文地址:https://arxiv.org/abs/2505.23754
数据地址:https://huggingface.co/datasets/Jiahao004/DeepTheorem
代码地址:https://github.com/Jiahao004/DeepTheorem
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —

点亮星标
科技前沿进展每日见
