

同一天,国内大模型厂商扎堆发起了新模型。
AI「六小龙」中的 MiniMax 和月之暗面各自公布了开源新成果。
其中,MiniMax 启动了「MiniMax Week」,并在第一天开源了其最新的长上下文推理 LLM——MiniMax-M1。该模型支持全球最长的上下文窗口,包括 100 万 tokens 输入、8 万 tokens 输出。
不仅如此,MiniMax-M1 还实现了开源模型中最强的智能体工具使用能力。强化学习效率也惊人,仅仅需要 53.47 万美元即可完成训练。
目前,MiniMax-M1 已经集成到了 MiniMax Chat 中。

如此强大的 MiniMax-M1 有哪些亮点功能呢?首先,它支持 UI 组件聚焦(Spotlight),只需输入提示词,立即就可以构建一个具有基于画布的动画粒子背景的 HTML 页面。

其次,MiniMax-M1 支持交互式应用程序。比如要求它构建一个打字速度测试,很快就生成一个干净、实用的 Web 应用程序,可以实时跟踪 WPM(每分钟字数)。不需要插件,也不需要设置。

此外,MiniMax-M1 的可视化效果很强。比如输入提示词:创建具有基于画布的动画粒子背景的 HTML 页面,颗粒应平稳移动并在靠近时连接,在画布上添加中心标题文本。(Create an HTML page with a canvas-based animated particle background. The particles should move smoothly and connect when close. Add a central heading text over the canvas.)
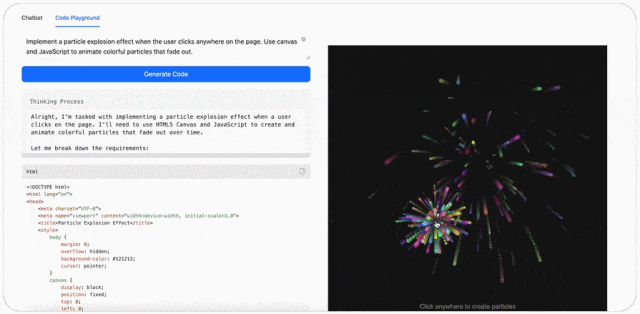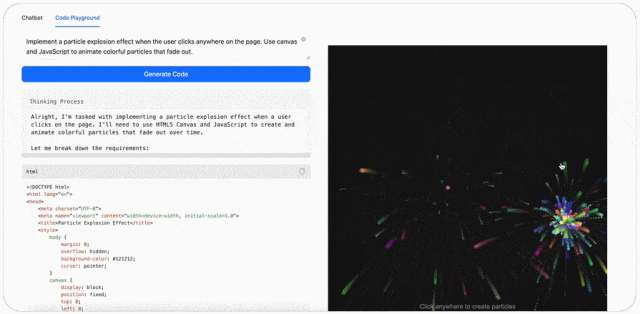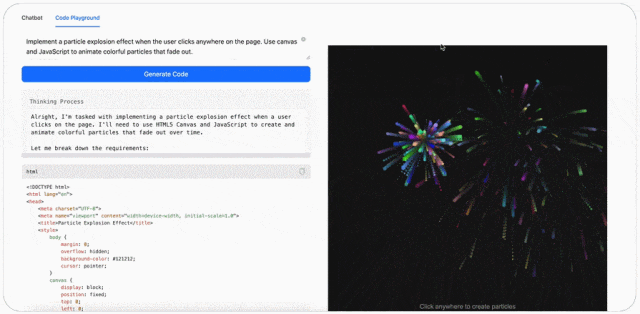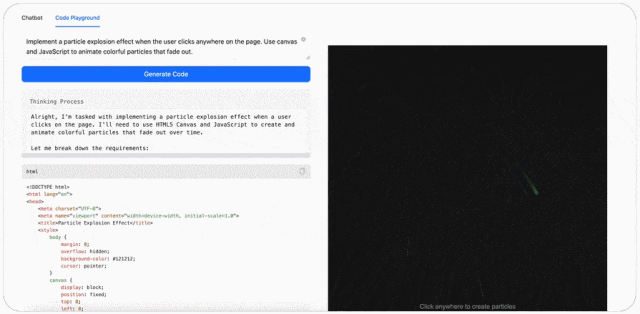
最后,MiniMax-M1 可以玩游戏。比如输入提示词:创建迷宫生成器和寻路可视化工具,随机生成一个迷宫,并可视化 A * 算法逐步解决它。使用画布和动画,使其具有视觉吸引力。(Create a maze generator and pathfinding visualizer. Randomly generate a maze and visualize A* algorithm solving it step by step. Use canvas and animations. Make it visually appealing.)
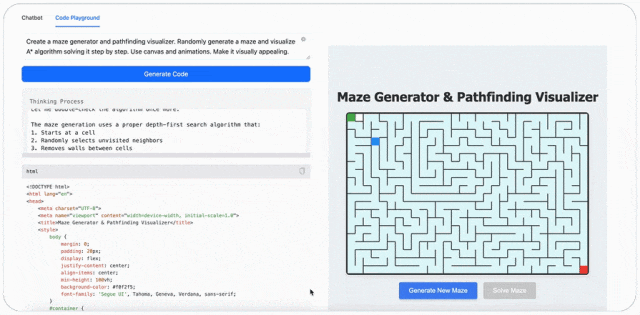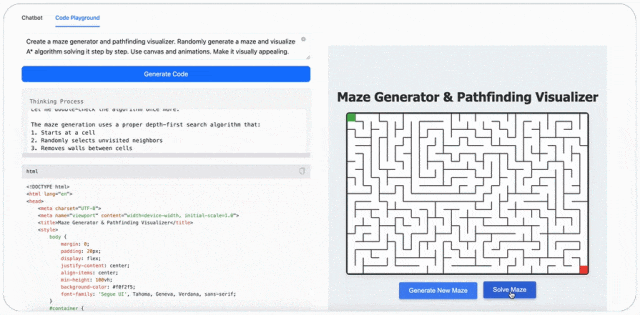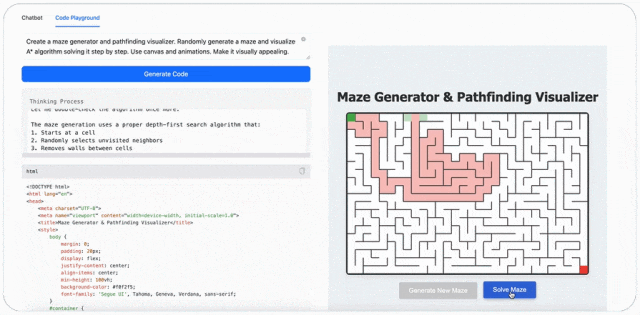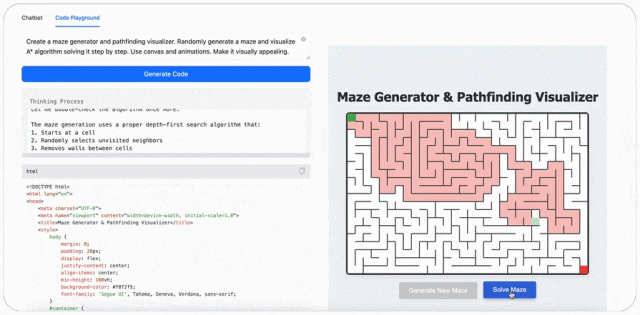
评论区的网友对 MiniMax-M1 也是翘首以盼,如今终于放出来了。
与此同时,月之暗面发布了强大的开源编程大模型 ——Kimi-Dev-72B。
在所有开源模型中,Kimi-Dev-72B 在代码生成评估基准 SWE-bench Verified 中取得了全新的 SOTA 分数。
目前,Kimi-Dev-72B 已向社区开放,以供进一步研发,主要资源包括了模型权重、源代码和技术报告(即将发布)。月之暗面希望开发者和组织能够探索、集成和扩展该模型的应用。
Hugging Face 地址:https://huggingface.co/moonshotai/Kimi-Dev-72B
GitHub 地址:https://github.com/MoonshotAI/Kimi-Dev
博客地址:https://moonshotai.github.io/Kimi-Dev/
面对同一天发布的这两个大模型,已经有人进行了代码实测 PK。
一位推特用户使用 three.js 生成拆烟囱 demo,结果显示,MiniMax-M1-80K 一把过,而 Kimi-Dev-72B 生成的代码需要使用 Claude-4-Sonnet 修复 3 个 bug 才能运行。

图源:https://x.com/karminski3/status/1934791130165727445
我们接下来介绍两款开源大模型的技术细节。
MiniMax-M1

Hugging Face:https://huggingface.co/collections/MiniMaxAI/minimax-m1-68502ad9634ec0eeac8cf094
GitHub 地址:https://github.com/MiniMax-AI/MiniMax-M1
技术报告:https://github.com/MiniMax-AI/MiniMax-M1/blob/main/MiniMax_M1_tech_report.pdf
体验地址:https://chat.minimax.io/
MiniMax-M1 是全球首款开源权重的大规模混合注意力推理模型,由混合专家(MoE)架构与闪电注意力机制共同驱动。该模型基于此前的 MiniMax-Text-01 模型开发而来,总参数量为 456 B,每个 token 激活 45.9 B 参数。
与 MiniMax-Text-01 一致,M1 模型原生支持 100 万 token 的上下文长度,是 DeepSeek R1 上下文规模的 8 倍。

此外,MiniMax-M1 中采用的闪电注意力机制实现了测试时计算成本的高效扩展 —— 例如,在生成长度为 10 万 token 时,M1 所消耗的浮点运算次数(FLOPs)仅为 DeepSeek R1 的 25%。这些特性使得 M1 尤其适用于需要处理长输入并进行深度思考的复杂任务。
MiniMax-M1 在从传统数学推理到基于沙盒的真实世界软件工程环境等各种问题上,均采用了大规模强化学习(RL)进行训练。MiniMax 为 M1 开发了一个高效的强化学习扩展框架,重点突出以下两个方面:
1. 提出了一种名为 CISPO 的新颖算法,该算法通过裁剪重要性采样权重而非 token 更新来优化模型。 在 AIME 的实验中,研究团队发现这比包括字节近期提出的 DAPO 等强化学习算法收敛性能快了一倍,显著的优于 DeepSeek 早期使用的 GRPO。

2. MiniMax 的混合注意力设计天然地提升了强化学习的效率,在此过程中,解决了在混合架构下扩展强化学习时遇到的独特挑战。
整个强化学习阶段只用到 512 块 H800 三周的时间,租赁成本只有 53.47 万美金,这比一开始的预期少了一个数量级。MiniMax 训练了两个版本的 MiniMax-M1 模型,分别具有 40k 和 80k 的思考预算。
在标准基准测试上的实验表明,该模型在性能上超越了其他强大的开源权重模型,如原始的 DeepSeek-R1 和 Qwen3-235B,尤其在复杂的软件工程、工具使用和长上下文任务上表现突出。
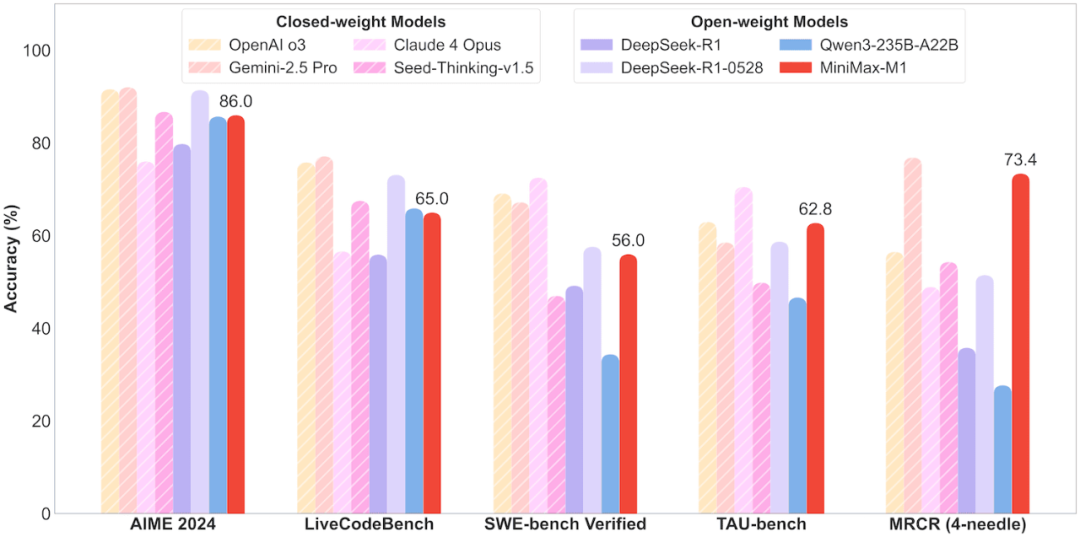
对领先的商业模型与开源模型在竞赛级数学、编程、软件工程、智能体工具使用以及长上下文理解等任务中的基准性能进行对比评估。其中,MiniMax-M1 结果使用其 MiniMax-M1-80k 模型。
MiniMax 在 17 个业内主流评测集上对 M1 模型进行了全面评估,结果显示,M1 在软件工程、长上下文处理和工具使用等面向生产力的复杂场景中,拥有显著优势。
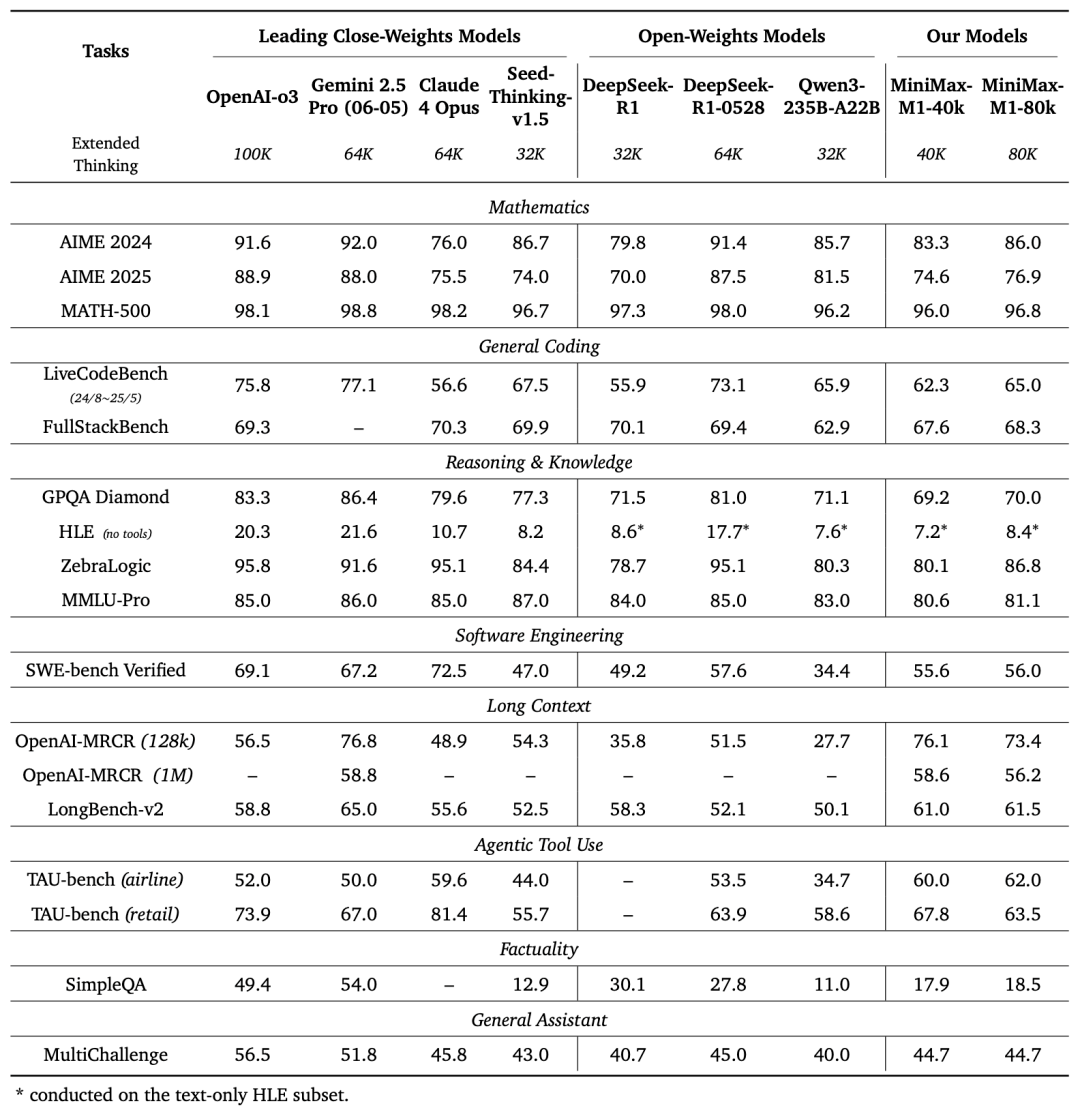
MiniMax-M1-40k 和 MiniMax-M1-80k 在 SWE-bench 验证基准上分别取得 55.6% 和 56.0% 的优异成绩,这一成绩略逊于 DeepSeek-R1-0528 的 57.6%,但显著超越其他开源权重模型。
依托其百万级上下文窗口,M1 系列在长上下文理解任务中表现卓越,不仅全面超越所有开源权重模型,甚至超越 OpenAI o3 和 Claude 4 Opus,全球排名第二,仅以微弱差距落后于 Gemini 2.5 Pro。
在代理工具使用场景(TAU-bench)中,MiniMax-M1-40k 同样领跑所有开源权重模型,并战胜 Gemini-2.5 Pro。
值得注意的是,MiniMax-M1-80k 在大多数基准测试中始终优于 MiniMax-M1-40k,这充分验证了扩展测试时计算资源的有效性。
MiniMax 还采取了极具诚意的开放策略:新模型在 MiniMax APP 和 Web 上都保持不限量免费使用,并以业内最低的价格在官网提供 API。

前面两种模式都比 DeepSeek-R1 性价比更高,后面一种模式 DeepSeek 模型不支持。
发布 M1 只是一个开始。据 MiniMax 透露,在接下来的数个工作日内,还将公布一系列令人期待的技术更新,敬请关注。
Kimi-Dev-72B
作为一个强大的开源 LLM,Kimi-Dev-72B 具有以下亮点:
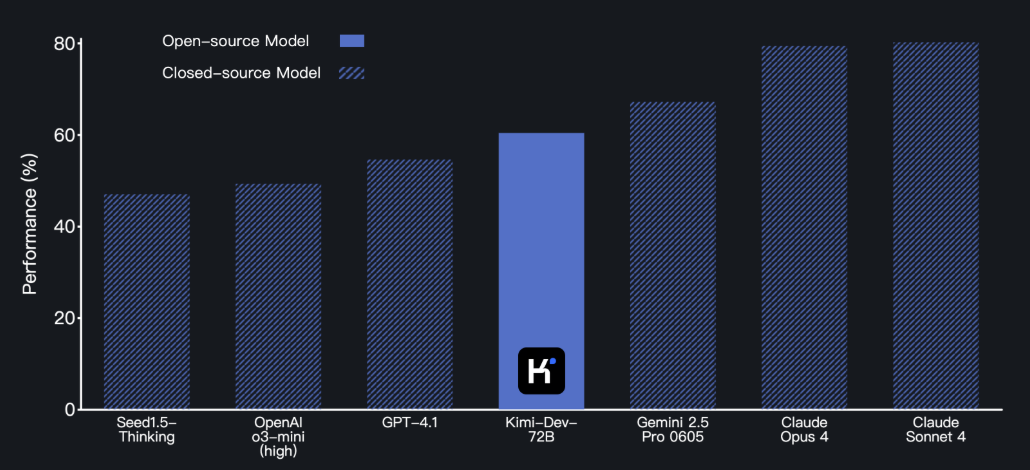
Kimi-Dev-72B 在 SWE-bench Verified 上取得了 60.4% 的成绩,在开源模型中创下了新的 SOTA 纪录。
Kimi-Dev-72B 通过大规模强化学习进行优化。它能够自主在 Docker 中修补真实代码仓库,并且只有在整个测试套件通过的情况下才会获得奖励。这确保了其提供的解决方案是正确且稳健的,符合现实世界中的开发标准。
Kimi-Dev-72B 可在 Hugging Face 和 GitHub 上下载和部署。
下图为 SWE-bench Verified 基准上,Kimi-Dev-72B 与其他开源模型的性能比较。

下图为 SWE-bench Verified 基准上,Kimi-Dev-72B 与闭源模型的性能比较。
以下是 Kimi-Dev-72B 的设计理念与技术细节,包括 BugFixer 与 TestWriter 的协作机制、中期训练、强化学习以及测试阶段自博弈等内容。
BugFixer 与 TestWriter 的协作机制
一个成功的漏洞修复补丁,应该能够通过准确反映该漏洞的单元测试。同时,一个成功的测试用例在复现漏洞时应能触发断言错误,并且在正确的补丁应用到代码库后能够通过测试。这就形成了 BugFixer 和 TestWriter 的互补角色:BugFixer 负责修复问题,TestWriter 负责验证和复现问题。一个足够强大的编程 LLM 应当在这两方面都表现出色。
BugFixer 和 TestWriter 遵循着相似的流程:它们都需要先找到正确的待编辑文件,然后执行相应的代码更新 —— 无论是修正脆弱的代码实现(BugFixer 的任务),还是插入单元测试函数(TestWriter 的任务)。
因此,为了同时支持这两个角色,Kimi-Dev-72B 采用了一个统一的极简框架,该框架仅包含两个阶段:(1) 文件定位 (File Localization) 和 (2) 代码编辑 (Code Edits)。BugFixer 与 TestWriter 的这种协作机制的设计,为 Kimi-Dev-72B 的整体架构奠定了基础
中期训练
为了提升 Kimi-Dev-72B 作为 BugFixer 和 TestWriter 的基础能力,使用了约 1500 亿个 token 的高质量真实世界数据对其进行了中期训练。以 Qwen 2.5-72B 作为基础模型,收集了数百万个 GitHub 上的问题报告 (issues) 和拉取请求中的代码提交记录 (PR commits) 作为中期训练数据集。
该数据配方经过精心设计,旨在让 Kimi-Dev-72B 学习人类开发者如何根据 GitHub 问题进行推理、构建代码修复方案以及编写单元测试。此外还进行了严格的数据去污染处理,以排除任何来自 SWE-bench Verified 测试集的代码仓库。
中期训练充分增强了基础模型在实用性错误修复和单元测试方面的知识,使其成为后续强化学习(RL)训练的更佳起点。
大规模强化学习
通过适当的中期训练和监督微调 (SFT),Kimi-Dev-72B 在文件定位 (File Localization) 方面已取得了优异的性能。因此,强化学习 (RL) 阶段专注于提升其代码编辑 (Code Edits) 的能力。
月之暗面采用了一种在 Kimi k1.5 中描述过的策略优化方法,该方法已在推理任务中展现出卓越成果。针对 SWE-bench Verified 测试基准,重点介绍以下三项关键设计:
仅基于结果的奖励机制(Outcome-based Reward Only)。只采用 Docker 最终执行结果(0 或 1)作为奖励信号,在训练过程中不使用任何基于格式或过程的奖励。这意味着,只有当模型生成的补丁能够使所有测试用例通过时,才会获得奖励,从而确保模型关注于实际有效的代码修复结果。
高效的提示集(Efficient Prompt Set)。过滤掉了模型在多样本评估中成功率为零的提示(即过于困难的任务),从而能够更有效地利用大批量数据进行训练。同时应用了课程学习策略,即逐步引入新提示,渐进式地增加任务难度。
正面范例强化(Positive Example Reinforcement)。在训练的最后阶段,将先前迭代中近期成功的样本重新加入到当前的训练批次中。这有助于模型巩固成功的模式并提升性能。
Kimi-Dev-72B 通过使用高度并行、强大且高效的内部智能体基础设施,从可扩展数量的问题解决任务训练中受益匪浅。
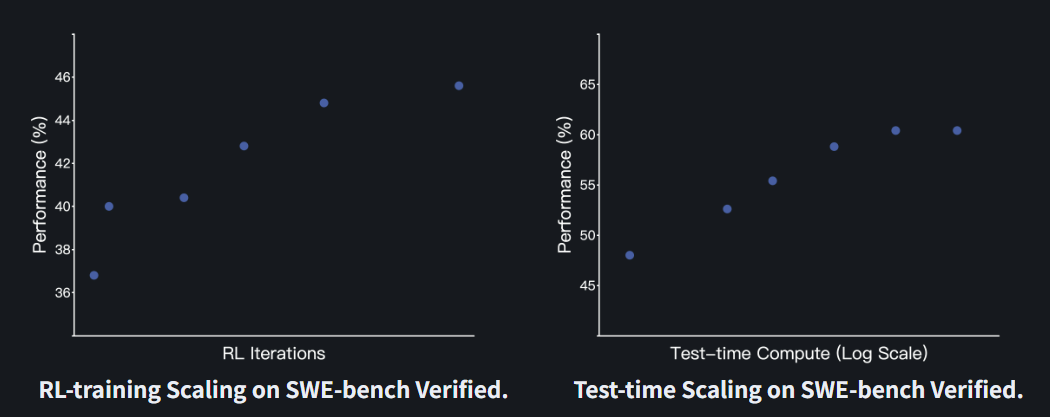
测试时自博弈(Test-time Self-Play)
经过强化学习后,Kimi-Dev-72B 能够同时掌握 BugFixer 和 TestWriter 的角色。在测试过程中,该模型会采用自博弈机制,协调自身 Bug 修复和测试编写的能力。

BugFixer 和 TestWriter 之间的测试时 self-play。
每个问题最多可以生成 40 个补丁候选和 40 个测试候选(按照标准 Agentless 设置),可以观察到测试时自博弈的扩展效应。
下一步计划
最后,月之暗面表示,他们正在积极研究和开发扩展 Kimi-Dev-72B 功能的方法,并探索更复杂的软件工程任务。未来的迭代将侧重于与流行的 IDE、版本控制系统以及 CI/CD 流水线进行更深入的集成,使 Kimi-Dev-72B 更加无缝地融入开发人员的工作流程。
在持续改进 Kimi-Dev-72B 的同时,月之暗面还将进行严谨的红队测试,并向社区发布更强大的模型。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com