

Scaling Law撞墙,扩展语言智能体的推理时计算实在太难了!破局之道,竟是使用LLM作为世界模型?OSU华人团队发现,使用GPT-4o作为世界模型来支持复杂环境中的规划,潜力巨大。
Scaling Law又能续命了?
如何通过语言智能体的高级规划来Scaling推理时计算?
答案就是——使用LLM作为世界模型。
也就是说,使用GPT-4o来预测网站上操作的结果,可以提供强大的性能,同时还能提高安全性和效率。
近日,来自俄亥俄州立大学等机构的研究人员提出了一种全新的WebDreamer框架,它可以利用LLM作为世界模型,来预测网站上的交互结果。

论文地址:https://arxiv.org/abs/2411.06559
几天前,微软Ignite大会上,纳德拉曾表示,AI发展并没触及天花板,我们正见证推理时计算Scaling law的崛起。

没错,这项新研究便是朝着这个方向前进的一步。
01 语言智能体和数学推理的关键区别,就是交互
一作Yu Gu表示,自从o1发布以来,这个问题就一直困扰着自己——

为什么扩展语言智能体的推理时计算,会如此困难呢?语言智能体,到底有何特别之处?
为此,他将这个问题进行了分解。
与数学推理等任务不同,语言智能体的一个关键区别在于交互:它们采取的每个动作,都会触发对环境的新观察,从而为自己的下一个决策提供信息。
而交互使得搜索空间探索变得复杂,原因在于——
1. 与环境的交换是昂贵的
2. 许多操作是状态改变且不可逆转的(比如在购物网站上确认购买),这就使得树搜索中的回溯,在现实世界的网站中不可行。

那么,是否可以使用LLM作为世界模型,来预测网站上交互的结果呢?(比如「如果单击此按钮,会发生什么」)
这样,就可以实现有效的搜索空间探索,减少实际交互的开销。
答案是肯定的!
Yu Gu等人发现,GPT-4o有效地编码了关于网站的广泛知识,并且充当了基于模型的规划框架WebDreamer的基础。
因为配备了LLMs模拟的世界模型,WebDreamer展示了良好的有效性和效率。
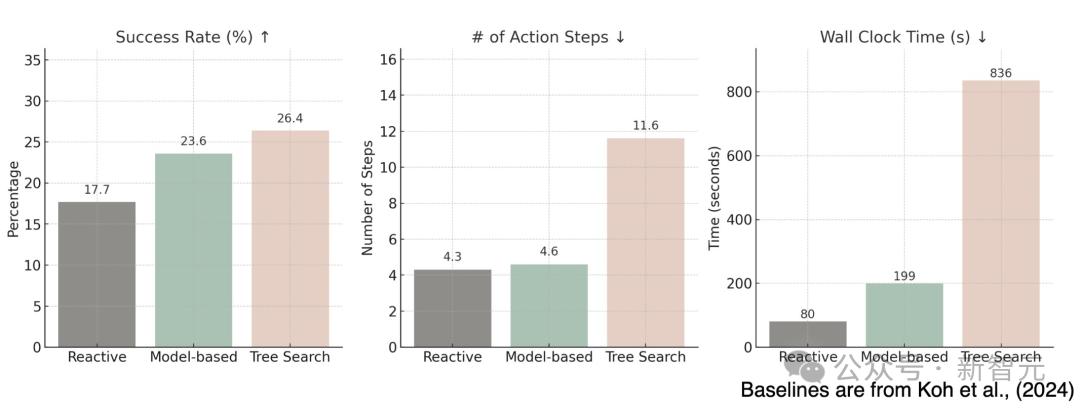
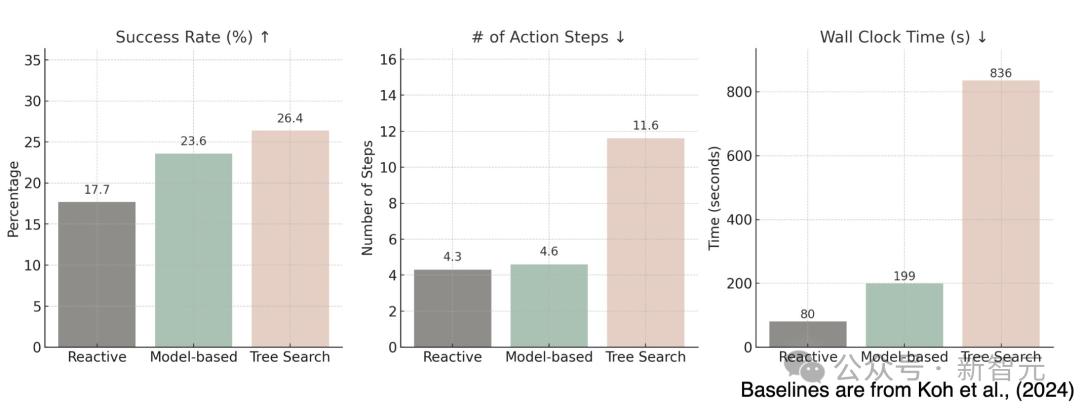
首先,它有着强大的性能:在VisualWebArena和Mind2Web-live上远远优于反应性基线。

在效率上,跟树搜索相比,它只需要一半的交互次数。
此外,由于基于LLM的世界模型模拟,它还具有两个额外的优势。
一个是更好的安全性,因为能通过最大限度地减少现实世界的互动,来降低安全风险。
另一个就是多功能集成:它可以作为各种智能体的插件无缝工作,并且对树搜索智能体有所补充。
02 WebDreamer的核心,就是「做梦」
智能体也需要做梦吗?
与数学推理等任务不同,语言智能体(language agents)的一个关键区别在于交互:他们采取的每一个行动都会触发环境的新变动,而这又为它进行进一步的决策带来了挑战。
不断地交互使得解空间搜索变得异常艰难,因为与环境交互的计算成本很高;许多改变状态的操作是不可逆的;而且利用智能体来为自己与网站进行实际交互有一定的安全风险,例如信息泄露与个人财产在意外交易中损失。
如何有效的进行解空间搜索,同时减少实际交互的开销并保证智能体的安全可靠性成了一个亟待解决的问题。
简要来讲,WebDreamer的核心是「做梦」的概念:在承诺采取任何行动之前,智能体使用LLM去想象预测每个可能步骤的结果,并以自然语言描述状态将如何变化。
然后,依据和实现目标任务的距离来对这些模拟结果进行评估。最后执行最有可能实现目标任务的模拟行动。这个过程会反复进行,直到LLM确定目标已经实现为止。
图1为网页智能体以搜索问题形式表现的不同策略示意图,其中每个节点代表一个网页。
为清晰起见,仅描述了一步模拟结果。褪色节点表示未浏览的网页,绿色对号和红色叉号分别表示成功和不成功的结果。
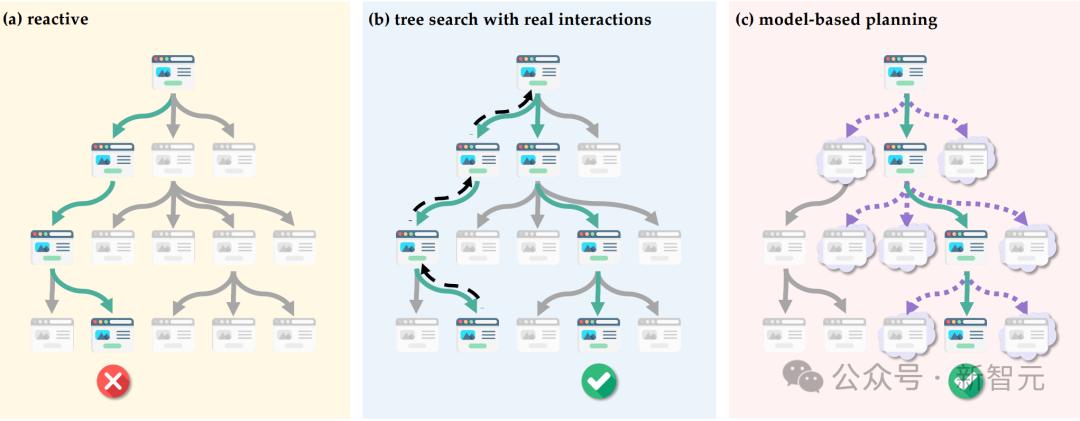
图1(a)反应式:由于智能体总是选择局部最优,没有前瞻性规划,往往导致次优结果。
图1(b)结合真实交互的树搜索:智能体通过主动网站导航探索多条路径,并允许回溯(用虚线箭头表示)。然而,在现实世界的网站中,由于不可逆操作的普遍存在,回溯往往不可行。
图1(c)基于模型的规划:在实际执行之前,智能体会模拟潜在的结果(如云状节点所示),以确定最佳行动,从而在保持有效性的同时尽量减少实际的网站交互。
总结来说,在LLM模拟的世界模型加持下,WebDreamer展现出了卓越的性能与效率,以及强大的扩展能力:
性能:在 VisualWebArena 和 Mind2Web-live 上表现远超反应式基线模型。
效率:与树搜索相比,仅需一半的交互次数。
安全:通过减少现实世界的交互,有效降低安全风险。
集成:可无缝作为多种智能体的插件运行,并补充树搜索智能体的功能。
03 准备
任务制定
对于在网站上进行实时自动化交互这一目标任务来讲,网页智能体面临着庞大且复杂的搜索解空间。
形式上,每个带有任务指令I的任务可以被视为一个部分可观测的马尔可夫决策过程(POMDP):(S, A, O, T, R, Ω)。
其中,S代表环境中所有可能状态的集合,A代表智能体可以采取的所有可能动作,O代表环境中所有可能的观测值组成的集合,T : S × A → S代表状态转移函数,R是一个二值reward,表示任务I是否已完成,Ω : S → O是一个可将状态投射到观测值的确定性函数。
任务的目标是执行一系列动作以获得1的奖励。
在实际场景中,由于网络环境的复杂性,其包括服务器端变量、动态加载的内容、隐藏的UI元素,并受网络条件和浏览器限制的影响,智能体只能通过有限的视角(即o ∈ O)来感知网络环境。
这种受限的观测视角也形成了相应的动作空间A,其包括可在o中可执行的交互操作,如点击、文本输入和URL跳转。

表1 在VisualWebArena中定义的网络导航动作空间
通过模拟进行规划
通过使用由状态转移函数「T」控制的真实交互进行树搜索来规划最优动作序列代价高昂,并且存在不可逆风险。基于模型的规划通过使用环境的计算表征来模拟交互结果,从而解决这些挑战。
一种显著的方法是模型预测控制(Model Predictive Control,MPC),它通过迭代模拟未来轨迹来选择动作。
对于每个状态s,MPC使用模拟器函数sim(s, a)在有限的预测范围H内模拟每个可能动作a ∈ A的轨迹,并使用评分函数score(τ)进行评估。然后执行最有前景的轨迹相应的动作:

此过程在观察到新状态后重复进行,从而使智能体能够根据实际结果调整其计划,同时避免代价高昂的真实世界探索。实际上,由于部分可观察性,我们无法访问真实状态,因此我们使用o = Ω(s)进行sim(o, a)的计算。
04 基于模型规划的网络智能体
作者利用LLM作为世界模型,提出了一种开创性方法:WebDreamer,以实现复杂网络环境中的高效规划。
该方法受到这样一个现象的启发:尽管网络界面复杂,但其设计对于人类用户来说是可预测的。
当浏览网站时,人类可以根据视觉提示和常见设计模式有效地预测动作结果——点击「提交」按钮即可提交表单,选择产品图片会导航到其详情页面。
鉴于LLMs是在大量Web相关数据上训练的,作者假设它们已经获得了足够的知识来模拟用户行为的后果,足以作为世界模型胜任有效规划。
核心设计
WebDreamer的核心,是利用LLM来实现模拟函数sim和评分函数score。
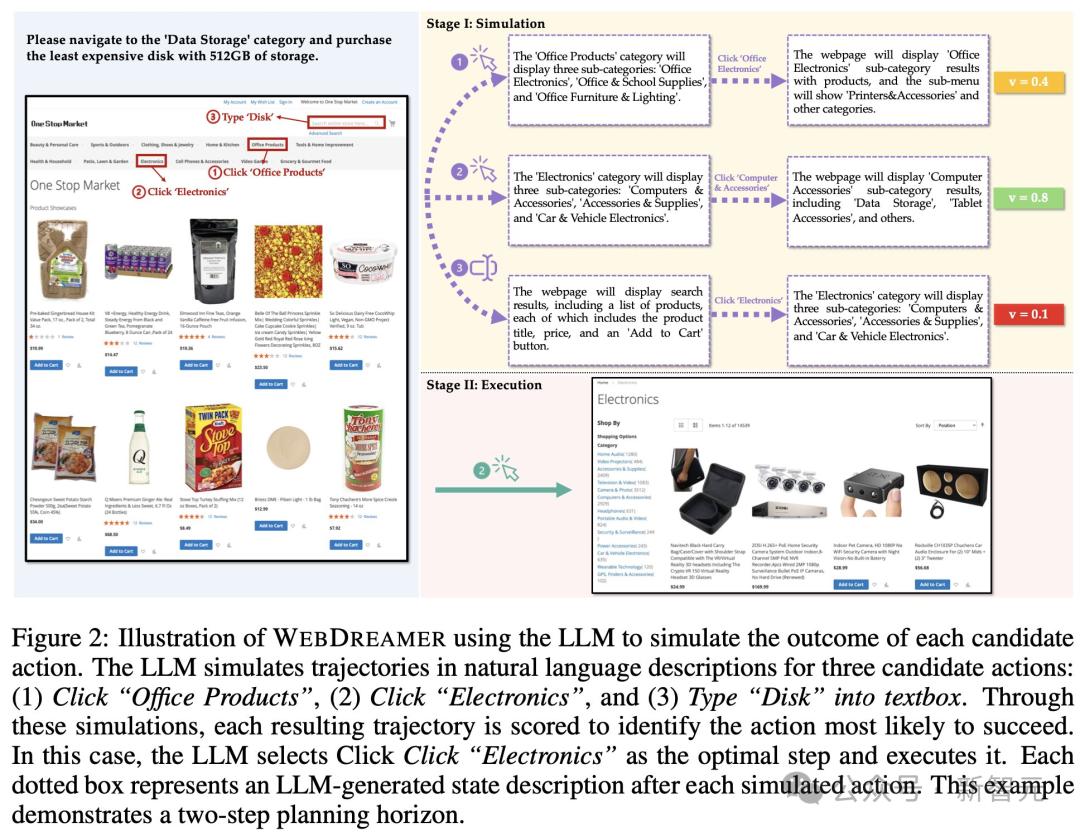
下图为WebDreamer使用LLM模拟三个候选动作的结果图示,其中WebDreamer模拟每个动作的两步轨迹,选择得分最高的轨迹,并执行相应的初始动作。
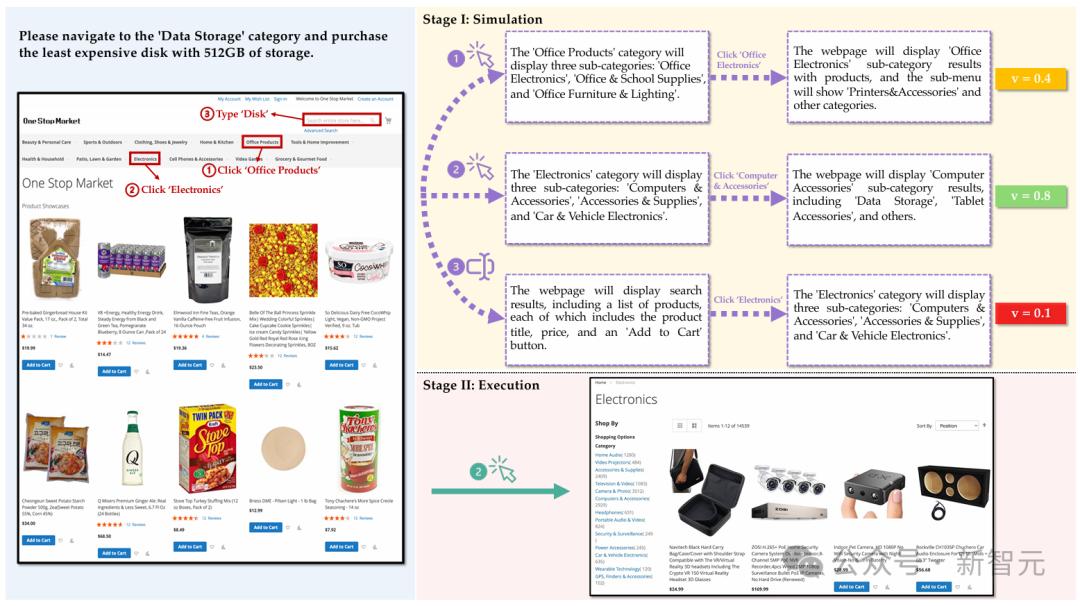
图中说明了LLM模拟自然语言描述中三个候选操作的轨迹:
(1)单击「Office Products」
(2)单击「Electronics」
(3)在文本框中键入「Disk」
通过这些模拟,对每个结果轨迹进行评分,以确定最有可能成功的动作。
在这种情况下,LLM选择单击「Electronics」作为最佳步骤并执行它。每个虚线框表示每个模拟操作后LLM生成的状态描述。
sim的实现
模拟函数sim的实现由两个模块组成:一个模块预测动作执行后的状态变化,近似状态转移函数「T」;而另一个根据预测的状态想象可能的动作。
这两个模块共同生成长度为H的轨迹,其中H是一个可配置的模拟深度参数。
具体来说,为了表示状态变化,研究者会提示LLM生成一个简明的自然语言描述,仅关注动作的效果。
例如,在图2中,当提示预测执行动作单击「Electronics」的效果时,LLM将输出如下简短描述:

基于这个预测的状态,LLM会随后想象下一个动作(例如,点击「电脑及配件」),这将导致另一个状态改变进一步的预测。
这个过程生成了一个模拟深度为H=2的轨迹。
score的实现
在使用sim从每个候选动作ai模拟出一个轨迹τi后,研究者进一步使用LLM作为每个模拟轨迹的评分函数。
他们提示LLM以三种评分标准,来评估每个模拟轨迹——完成(1.0)、进行中(0.5)或不正确(0),以指示其任务完成的进度。
最终得分通过对这些评估的多次采样进行平均计算。除了sim和score,规划的一个前提是候选动作生成。
研究者采用了两阶段方法:首先采样出前k个动作,然后使用LLM自我优化,去除不必要的动作以进行模拟。
这个自我优化步骤的动机,是研究者观察到在不同步骤中,相同的k可以引入不同程度的不相关动作——某些步骤本身就比其他步骤可以用更少的有效动作进行实现。
在算法1中,他们展示了WebDreamer整体设计的伪代码。termination check用于验证模型是否输出停止动作,其规则为当算法达到最大步骤或连续3次重复一个动作时,则停止继续执行算法。

完整system prompts如下:




05 实验结果
有效性
如表2所示,WebDreamer在VWA和Mind2Web-live数据集上相较于反应式智能体表现出显著的改进:
在VWA数据集上,实现了33.3%的相对性能提升
在Mind2Web-live数据集上,相较于Reactive范式提升了2.9%(相对增益为13.1%)
虽然在总体成功率方面,还是基于树搜索的方案更高,但它实际上并不适用于真实的网络场景。而WebDreamer则可以提供一种更灵活且适应性更强的替代方案。

表2:VisualWebArena和Mind2Web-live的结果
更进一步,研究人员将WebDreamer与Reactive范式在VWA数据集上的多维度表现进行了比较。
表3显示,基于模型的规划方法在所有网站和任务难度级别上都始终优于基于Reactive范式的方法 。
在根据VWA官方标注的中等难度任务中,基于模型的规划甚至超过了树搜索方案的表现(24.1% VS 22.2%)。
指标

用于衡量基于模型的规划与树搜索方案的相对性能表现。

表3:不同维度对应的成功率
效率
基于模型的规划的另一个关键优势是其相对于树搜索,执行任务时效率很高。
如表4所示,树搜索在所有环境中所需的步骤大约是baseline的三倍,而WebDreamer的相应动作步骤数与baseline则相仿。
值得注意的是,由于额外的动作和回溯,树搜索会引入大约十倍的实际时间延迟,而WebDreamer的模拟开销很小,并且可以通过增强并行化进一步减少。

表4:VWA上的动作步骤和总耗时
案例研究
为了阐明模拟在规划中的作用,研究者提出了包含正面和反面例子的案例研究,说明了模拟如何帮助智能体探索环境,以及模拟的不准确性会如何导致错误的预测。
由建构不充分的世界模型进行模拟引起的错误如下:
研究者给智能体的指令是:给我找一台与图片中产品相同品牌的打印机。它必须是白色的,并且至少有11条评论,平均评分大于4分。

受益于世界模型模拟的正面案例如下:
在这个案例中,智能体正确找到了两种前面有鸟的衬衫。

06 作者介绍
Yu Gu(谷雨)

Yu Gu是俄亥俄州立大学的博士生,此前在南京大学获得了计算机科学学士和硕士学位。

Boyuan Zheng

Boyuan Zheng目前是俄亥俄州立大学的一年级博士生,由Yu Su教授指导。
在此之前,他获得了东北大学的软件工程学士学位,以及约翰霍普金斯大学的计算机科学硕士学位,在那里他与Benjamin Van Durme教授合作。

他的主要研究方向是开发能够解放人类从繁琐任务中并辅助决策的语言智能体,尤其是在网络环境中。其他还有多模态,基础、规划与推理,合成数据和智能体安全。
参考资料:
https://arxiv.org/pdf/2411.06559
本文来自微信公众号“新智元”,作者:新智元,36氪经授权发布。