

【导读】近日,中国科学院计算技术研究所联合软件研究所推出「启蒙」系统,基于AI技术,实现处理器芯片软硬件各个步骤的全自动设计,达到或部分超越人类专家手工设计水平。
芯片设计向来是科技界的「皇冠明珠」,传统设计流程需要顶尖专家团队耗时数月甚至数年攻坚,极具挑战性。
芯片设计包含多个关键步骤,硬件设计方面包括逻辑设计、电路设计、物理设计等,基础软件方面包括操作系统内核设计、编译工具链设计、高性能库设计等。
中国科学院计算技术研究所处理器芯片全国重点实验室,联合中国科学院软件研究所,基于大模型等AI技术,推出处理器芯片和相关基础软件全自动设计系统——「启蒙」。
「启蒙」系统可以全自动的实现芯片软硬件设计各个步骤,达到或部分超越人类专家手工设计水平。
具体而言,「启蒙」系统已实现自动设计RISC-V CPU,达到ARM Cortex A53性能,并能为芯片自动配置操作系统、转译程序、高性能算子库,性能优于人类专家设计水平。
这项研究有望改变处理器芯片软硬件的设计范式,不仅有望大幅提升设计效率、缩短设计周期,同时有望针对特定应用场景需求实现快速定制化设计,灵活满足芯片设计日益多样化的需求。

论文地址:https://arxiv.org/abs/2506.05007

处理器芯片软硬件全自动设计
众所周知,芯片设计是一项非常具有挑战性、需要耗费大量人力和资源的工作。
芯片硬件设计依赖工程师团队编写等硬件描述代码(如Verilog、Chisel等),通过电子设计自动化(EDA)工具生成电路逻辑,并反复进行功能验证和性能优化。
这一过程高度专业化且复杂,通常需上百人团队耗时数月甚至数年,成本极高[1]。
同时,当前芯片基础软件适配需求激增。AI、云计算和边缘计算等技术推动专用处理器设计多样化,指令集组合呈指数级增长,每种组合均需适配庞大的基础软件栈。
传统设计范式下,软件生态适配周期长、成本高,严重制约硬件算力释放。以openEuler为例,其包含1万余软件仓库、400余万文件,需针对不同RISC-V指令组合逐一验证兼容性。
为了减少芯片软硬件设计的人力和资源投入,满足芯片设计日益多样化的需求,研究人员基于AI技术,构建国际首个全自动的处理器芯片软硬设计系统「启蒙」。
基于「启蒙」系统,芯片软硬件设计的各个环节都能实现全自动完成,设计成果可比肩甚至超过人工专家设计水平。

图1 启蒙1号实物图,启蒙1号和启蒙2号的性能对比
在芯片前端设计方面,实现国际首个全自动化设计的处理器核「启蒙1号」[2], 5小时内完成32位RISC-V CPU的全部前端设计,达到Intel 486性能,规模超过4,000,000个逻辑门,已完成流片。
其升级版「启蒙2号」[3]为国际首个全自动设计的超标量处理器核,达到ARM Cortex A53性能,规模扩大至17,000,000个逻辑门。
在硬件代码自动生成方面,实现硬件代码自动生成大模型CodeV系列 [4,5],能同时完成Chisel、Verilog语言的代码自动生成与代码片段补全。其中,CodeV-R1在Verilog硬件代码生成领域达到7B量级国际最优水平,在RTLLM Benchmark上超越671B满血版DeepSeek-R1。
在自动操作系统配置优化方面,实现国际首个基于大模型的操作系统内核配置自动优化方法AutoOS [6],可自动生成定制优化后的操作系统内核配置,性能相比行业专家手工优化最高可提升25.6%。
在自动编译工具链设计方面,实现国际首个自动跨平台张量程序转译工具QiMeng-Xpiler [7],可在不同的处理器芯片如英伟达GPU、寒武纪MLU、AMD MI加速器、Intel DL Boost,和不同编程模型如SIMT、SIMD之间自动程序转译,性能最高达到厂商手工优化算子库的2倍。
同时实现国际首个基于大模型的端到端编译器 [8],成功实现真实编译数据集ExeBench中91%的编译任务。
在自动高性能库设计方面,提出国际首个基于大模型的高性能矩阵乘代码自动生成框架QiMeng-GEMM [9]和国际首个基于大模型的高性能张量算子指令级自动生成框架QiMeng-TensorOp [10],在RISC-V CPU上的最高性能分别达到OpenBLAS的211%和251%,在NVIDIA GPU上的最高性能分别达到cuBLAS的115%和124%。
启蒙的组成
大模型、智能体、应用三个层级
自动的电路逻辑设计长期以来都是计算机科学的核心问题之一[11]。现有自动设计方法通常将AI技术作为工具用于优化芯片设计的某个具体步骤。
不同于传统自动设计方法,「启蒙」系统旨在端对端的实现从功能需求到处理器芯片软硬件的全自动设计和适配优化。
然而,由于处理器芯片设计领域的特殊性,实现处理器芯片软硬件全自动设计主要面临数据稀缺、正确性和求解规模等方面的关键挑战。
为了应对上述挑战,建立处理器芯片软硬件全自动设计的新范式,「启蒙」共包含三个层级。底层为处理器芯片领域大模型,中间层构建芯片和软件智能体,实现处理器芯片和基础软件的自动设计,在最上层应用于芯片软硬件设计的各个步骤。
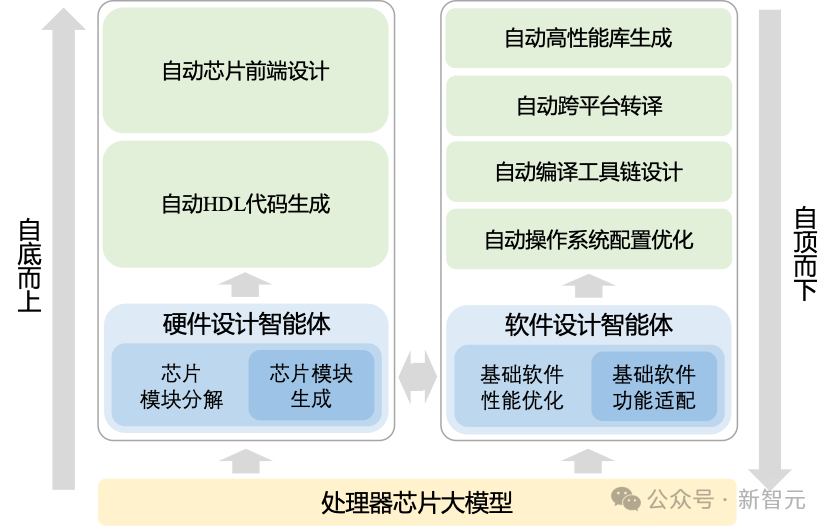
图2 「启蒙」系统的结构图,包含三个层级
处理器芯片大模型需要充分结合领域特点,掌握处理器芯片设计的领域知识,具备软硬件设计的基础能力。
此外,利用处理器芯片大模型构建反馈式推理流程,包括正确性反馈和性能反馈。通过自动功能验证和基于功能正确性反馈的自动修复,确保生成结果的正确性。同时通过自动性能评估和基于性能反馈的自动搜索,对解空间有效裁剪,实现对高性能设计结果的高效搜索。

图3 「启蒙」系统中的反馈式推理,包括正确性反馈和性能反馈
在处理器芯片大模型的基础上,为自动设计处理器芯片的软硬件,「启蒙」系统分别构建了芯片生成智能体和基础软件智能体。
结合反馈式推理能力,芯片生成智能体自动完成从功能需求到逻辑电路的设计,基础软件智能体自主完成给定基础软件对目标芯片的自动功能适配和性能优化。
基于芯片生成智能体和基础软件智能体,针对多样化的实际应用场景,在最上层全自动完成处理器芯片软硬件设计各个步骤。
启蒙的建立和展望
虽然「启蒙」系统的设计是自底而上的,但由于芯片软硬件设计领域的专业数据极为缺乏,
因此在具体实现时,采用自顶而下的构建方式更加容易切入。
以最顶层的多种应用实现为驱动,实现芯片软硬件各个步骤的自动设计方法后,不仅可以为处理器芯片大模型提供丰富的软硬件设计领域数据,同时也可以为处理器芯片智能体提供与专业工具协同交互的流程设计经验。
因此,「启蒙」系统采用「三步走」的技术路线:
(1)自顶而下:以通用大语言模型作为处理器芯片大模型的起点,实现处理器芯片智能体并完成处理器芯片软硬件各个步骤的自动设计。将各个步骤串联后自动产生丰富的跨层协同设计领域数据,用于训练处理器芯片大模型。
(2)自底而上:基于训练后的处理器芯片大模型重新构建智能体,并应用于软硬件设计的各个步骤,提升自动设计效果,
(3)自演进:将自顶而下和自底而上的设计流程组成迭代的循环,通过循环实现「启蒙」系统的自演进,不断提升「启蒙」系统的处理器芯片软硬件全自动设计能力。
目前,研究人员已基本完成第一步中软硬件各个步骤的自动设计。并且以3D高斯泼溅为驱动范例,将各个步骤串联,组成完整的软硬件协同设计流程[12]。后续将继续推进跨层协同设计数据集的建立和处理器芯片大模型的训练。
研究人员将继续实现从自顶而下到自底而上的设计路线,并组成迭代的循环,最终朝着实现整个「启蒙」系统自演进的目标迈进。
未来,还将通过符号主义、行为主义及连接主义等不同人工智能路径的交叉探索,不断提升「启蒙」系统的处理器芯片软硬件全自动设计能力,同时持续拓展「启蒙」的应用边界,为更广泛的处理器芯片设计应用场景提供智能化支持。
来源:新智元
参考资料:
[1] Bentley, B. Validating a modern microprocessor. In Proceedings of International Conference on Computer Aided Verification (CAV), 2–4 (2005).
[2] Cheng, S. et al. Automated cpu design by learning from input-output examples. In Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence, 3843–3853 (2024).
[3] Cheng, S. et al. QiMeng-CPU-v2: Automated superscalar processor design by learning data dependencies. In arXiv, https://arxiv.org/abs/2505.03195 (2025)
[4] Zhao, Y. et al. CodeV: Empowering llms for verilog generation through multi-level summarization. In arXiv, https://arxiv.org/abs/2407.10424 (2024)
[5] Zhu, Y. et al. CodeV-R1: Reasoning-Enhanced Verilog Generation. In arXiv, https://arxiv.org/abs/2505.24183 (2025)
[6] Chen, H. et al. AutoOS: make your os more powerful by exploiting large language models. In Forty-first International Conference on Machine Learning (2024)
[7] Dong, S. et al. QiMeng-Xpiler: Transcompiling tensor programs for deep learning systems with a neural-symbolic approach. In arXiv, https://arxiv.org/abs/2505.02146 (2025)
[8] Zhang, S. et al. Introducing compiler semantics into large language models as programming language translators: A case study of c to x86 assembly. In Findings of the Association for Computational Linguistics: EMNLP, 996–1011 (2024)
[9] Zhou, Q. et al. QiMeng-GEMM: Automatically generating high-performance matrix multiplication code by exploiting large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, 22982–22990 (2025)
[10] Zhang, X. et al. QiMeng-TensorOp: Automatically generating high-performance tensor operators with hardware primitives. In arXiv, https://arxiv.org/abs/2505.06302 (2025)
[11] Church, A. Applications of recursive arithmetic to the problem of circuit synthesis. Summaries of the Summer Institute of Symbolic Logic 1, 3-50 (1957)
[12] Chang, K. et al. Large processor chip model. In arXiv, https://arxiv.org/abs/2505.06302 (2025)
End

企业热点
歌尔股份2025年Q1财报:营收承压净利逆增
金运激光,请放弃在元宇宙概念股中挣扎!
AI大脑与双手?谈DeepSeek与Manus的博弈
“网游第一股”中青宝再次踏上“作死”之路
大空间情报
2024-2025年LBE VR大空间市场观察(综合篇)
从游轮到机场,VR大空间如何重构千亿级线下娱乐
同质化、低质化,VR大空间还能坚持多久?
90% VR大空间的失败,是因为这一点!
线上+线下,元宇宙已进化出“双形态”
行业解读
黑神话悟空帅爆了,元宇宙的春天也来了!
黑悟空带来的泼天富贵,文旅元宇宙要接住
“寸草不生”的元宇宙土地,还有得救!
两极分化!元宇宙企业进入第二轮“淘汰赛”
报告精选
《中国元宇宙政策研究报告2023》
《数字中国发展报告(2023年)》
《中国人工智能系列白皮书—元宇宙技术2024》
