

梦晨 发自 凹非寺
量子位 | 公众号 QbitAI
OpenAI前首席科学家、联合创始人Ilya Sutskever曾在多个场合表达观点:
只要能够非常好的预测下一个token,就能帮助人类达到通用人工智能(AGI)。
虽然,下一token预测已在大语言模型领域实现了ChatGPT等突破,但是在多模态模型中的适用性仍不明确。多模态任务仍然由扩散模型(如Stable Diffusion)和组合方法(如结合 CLIP视觉编码器和LLM)所主导。
2024年10月21日,智源研究院正式发布原生多模态世界模型Emu3。该模型只基于下一个token预测,无需扩散模型或组合方法,即可完成文本、图像、视频三种模态数据的理解和生成。
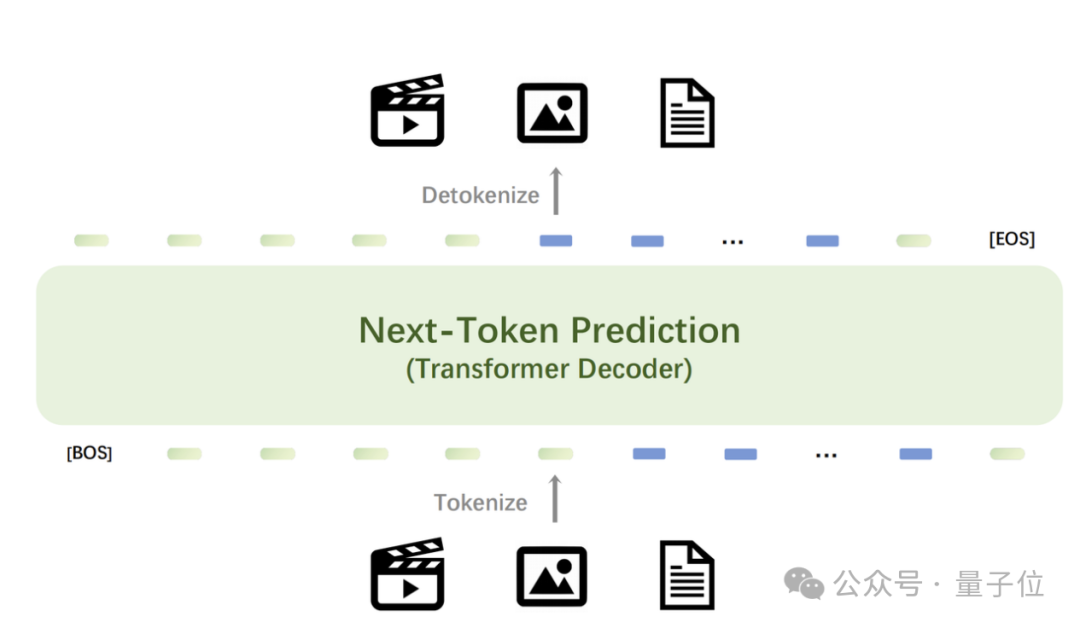
Emu3在图像生成、视频生成、视觉语言理解等任务中超过了SDXL 、LLaVA、OpenSora等知名开源模型,但是无需扩散模型、CLIP视觉编码器、预训练的LLM等技术,只需要预测下一个token。
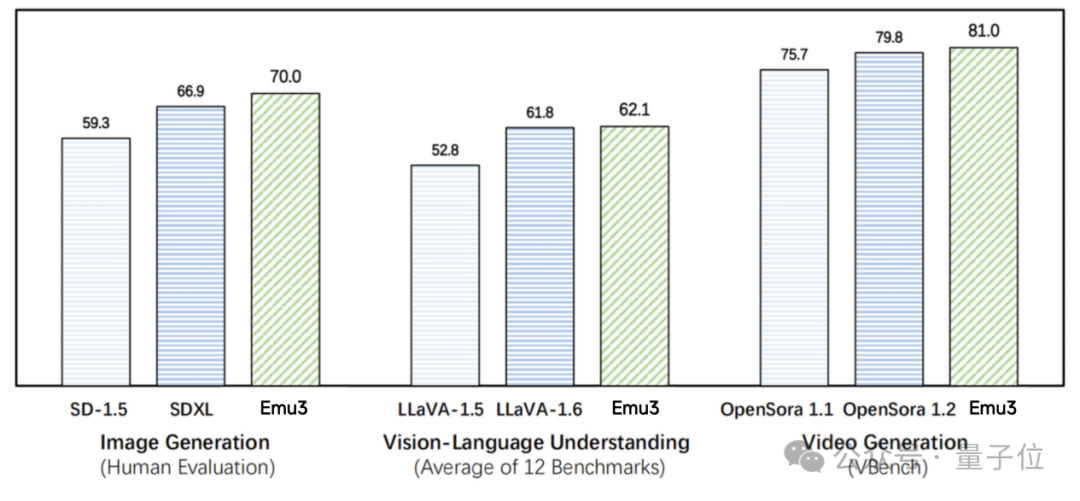
图注:在图像生成任务中,基于人类偏好评测,Emu3优于SD-1.5与SDXL模型。在视觉语言理解任务中,对于12 项基准测试的平均得分,Emu3优于LlaVA-1.6。在视频生成任务中,对于VBench基准测试得分,Emu3优于OpenSora 1.2。
Emu3提供了一个强大的视觉tokenizer,能够将视频和图像转换为离散token。这些视觉离散token可以与文本tokenizer输出的离散token一起送入模型中。与此同时,该模型输出的离散token可以被转换为文本、图像和视频,为Any-to-Any的任务提供了更加统一的研究范式。而在此前,社区缺少这样的技术和模型。
此外,受益于Emu3下一个token预测框架的灵活性,直接偏好优化(DPO)可无缝应用于自回归视觉生成,使模型与人类偏好保持一致。
Emu3研究结果证明,下一个token预测可以作为多模态模型的一个强大范式,实现超越语言本身的大规模多模态学习,并在多模态任务中实现先进的性能。通过将复杂的多模态设计收敛到token本身,能在大规模训练和推理中释放巨大的潜力。下一个token预测为构建多模态AGI提供了一条前景广阔的道路。
目前Emu3已开源了关键技术和模型。(开源模型和代码地址在文末)
Emu3一经上线便在社交媒体和技术社区引起了热议。

有网友指出,“这是几个月以来最重要的研究,我们现在非常接近拥有一个处理所有数据模态的单一架构。”
“Emu3 是一种非常新颖的方法(至少在我看来是这样),它有机会将多模态合并为一,只需将它们都视为token即可。虽然还处于初期,但演示效果很不错。想象一下,我们可以无限扩展视频和生成多种模态。”

甚至有网友评价:“也许我们会得到一个真正开放的 OpenAI v2?”

对于Emu3的意义和影响,有评论指出:“Emu3 将彻底改变多模态AI领域,提供无与伦比的性能和灵活性。”
“Emu3在各行各业的广泛适用性和开源灵活性将为开发者和企业解锁人工智能创新能力的机会。”
“对于研究人员来说,Emu3意味着出现了一个新的机会,可以通过统一的架构探索多模态,无需将复杂的扩散模型与大语言模型相结合。这种方法类似于transformer在视觉相关任务中的变革性影响。”

“Emu3的统一方法将带来更高效、更多功能的AI系统,简化多模态AI的开发和应用以及内容生成、分析和理解的新可能性。”
“Emu3 改写了多模态人工智能的规则…Emu3 重新定义了多模态AI,展示了简单可以战胜复杂。多模态AI的未来变得更加精炼与强大。”

效果展示1. 视觉理解
Emu3 展现了强大的图像及视频的感知能力,能够理解物理世界并提供连贯的文本回复。值得注意的是,这种能力是在不依赖于基础LLM模型和CLIP的情况下实现的。
1.1 图像输入

| 用户问题: Describe the landmark. |
| 模型回答: The image showcases the Brooklyn Bridge, a prominent suspension bridge in New York City, recognized by its distinctive towers and the web of cables that support it. This iconic structure connects the boroughs of Brooklyn and Manhattan. |

| 用户问题: Please describe the image in detail. |
模型回答: The image is the cover of a magazine titled “Parktakes,” which is the Fall 2017 issue. The cover features two individuals in a white kayak, paddling on a body of water. The kayak is positioned diagonally, with the two individuals seated towards the front. Both individuals are wearing life jackets, which are red with black straps, and they are holding paddles with orange blades. The person on the left is a woman with long dark hair, wearing sunglasses and a black top. The person on the right is a man with short hair, wearing a green shirt and a light-colored cap. They both appear to be smiling and enjoying their time on the water. The background shows a natural setting with trees and greenery, indicating that they are likely in a park or natural reserve. The water is calm, and the sky is not visible, suggesting a serene and peaceful environment. The magazine cover includes several text elements: 1. Title: “Parktakes” is prominently displayed at the top in large, bold, blue letters. 2. Fall 2017 Issue: The issue is marked in the top right corner in a smaller, white font. 3. Main Feature: “Enjoy Fall Adventures in Parks” is written in a large, bold, orange font, emphasizing the theme of outdoor activities. 4. Additional Features: The cover lists several topics covered in the magazine: - “Birding, Boating, and Hiking” - “Seasonal Festivals” - “New Attractions” 5. Registration Information: At the bottom, there is a call to action to “Registration begins Aug. 1 for full classes” and a website link: “www.fairfaxcounty.gov/parks.” Analysis and Description The cover of “Parktakes” effectively conveys the theme of outdoor recreational activities, particularly in parks. The image of the two individuals in a kayak suggests that the magazine features content related to kayaking, canoeing, and other water sports. The inclusion of life jackets indicates a focus on safety and preparedness for water activities. The mention of seasonal festivals and new attractions implies that the magazine includes information on various events and attractions within the parks. The cover also highlights the magazine’s commitment to providing a comprehensive guide to outdoor activities, with a clear emphasis on safety and accessibility. The registration information suggests that the magazine is a resource for planning and participating in various outdoor activities, likely targeting a wide audience interested in parks and recreational activities. In summary, the magazine cover is designed to attract readers interested in outdoor adventures, safety, and seasonal events within parks. The use of a kayak and life jackets emphasizes the magazine’s focus on water sports and safety, while the inclusion of various features and registration information suggests a well-rounded resource for park visitors. |
1.2 视频输入
| 用户问题: What is the man doing in the video? |
| 模型回答: The man in the video appears to be performing a fire dance, a form of entertainment where a person uses fire to create dynamic and visually appealing movements. The sparklers he holds produce a mesmerizing display of light and shadows, capturing the intensity of his performance. |
2. 图像生成
Emu3通过预测下一个视觉token来生成高质量的图像。该模型自然支持灵活的分辨率和不同风格。

3. 视频生成
与使用视频扩散模型以从噪声生成视频的Sora不同,Emu3只是通过预测序列中的下一个token来因果性的生成视频。
4. 视频预测
在视频的上下文中,Emu3可以自然地扩展视频并预测接下来会发生什么。模型可以模拟物理世界中环境、人和动物。
Emu3技术细节1 数据
Emu3是在语言、图像和视频混合数据模态上从头开始训练的。
语言数据:使用与Aquila模型相同的语言数据,一个由中英文数据组成的高质量语料库。
图像数据:构建了一个大型图像文本数据集,其中包括开源网络数据、AI生成的数据和高质量的内部数据。整个数据集经过了分辨率、图片质量、类型等方面的过滤过程。训练了一个基于Emu2的图像描述模型来对过滤后的数据进行标注以构建密集的图像描述,并利用vLLM库来加速标注过程。
视频数据:收集的视频涵盖风景、动物、植物和游戏等多个类别。
整个视频处理流程包括了场景切分、文本过滤、光流过滤、质量评分等阶段。并使用基于图像描述模型微调得到的视频描述模型来对以上过滤后的视频片段打标文本描述。
2 统一视觉Tokenizer
在SBER-MoVQGAN的基础上训练视觉tokenizer,它可以将4×512×512的视频片段或512×512的图像编码成4096个离散token。它的词表大小为32,768。Emu3的tokenizer在时间维度上实现了4×压缩,在空间维度上实现了8×8压缩,适用于任何时间和空间分辨率。
此外,基于MoVQGAN架构,在编码器和解码器模块中加入了两个具有三维卷积核的时间残差层,以增强视频token化能力。
3 架构
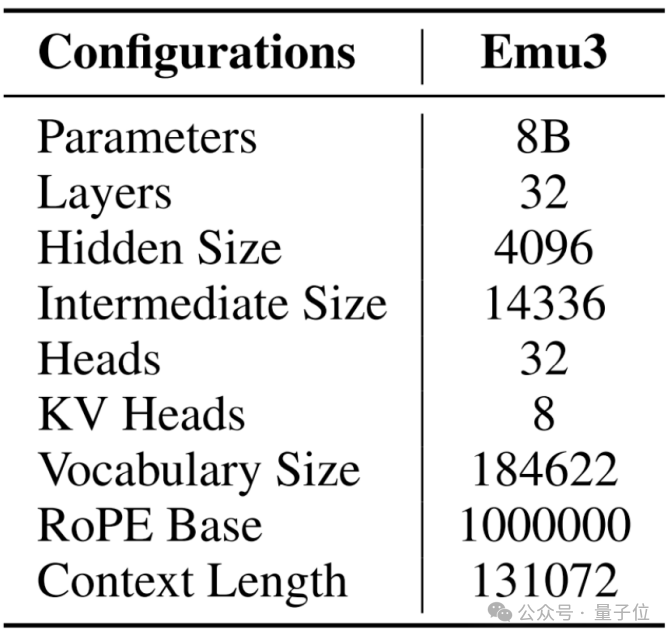
Emu3保留了主流大语言模型(即 Llama-2)的网络架构。不同点在于,其扩展了Llama-2架构中的嵌入层,以容纳离散的视觉token。网络中使用RMSNorm进行归一化。其还使用了GQA注意力机制、SwiGLU激活函数和一维旋转位置编码(RoPE)等技术,并并去除了注意力模块中QKV层和线性投影层中的偏置。此外,还采用了0.1的dropout率来提高训练的稳定性,使用QwenTokenizer对多语言文本进行编码。详细架构配置表。
4 预训练
在预训练过程中,首先要定义多模态数据格式。与依赖外部文本编码器的扩散模型不同,Emu3 原生集成了用于生成图像/视频的文本条件信息。在视觉和语言的固有token中新增了五个特殊token来合并文本和视觉数据,以为训练过程创建类似文档的输入。生成的训练数据结构如下:
[BOS] {caption text} [SOV] {meta text} [SOT] {vision tokens} [EOV] [EOS]
其中,[BOS] 和[EOS] 是QwenTokenizer中的原始特殊token 。
额外新增的特殊token包括:
[SOV]表示视觉输入(包含图像和视频的meta信息部分)的开始
[SOT]表示视觉token的开始
[EOV]表示视觉输入的结束。
此外,特殊token [EOL] 和[EOF] 作为换行符和换帧符插入到了视觉token中。元文本包含图像的分辨率信息,视频则包括分辨率、帧率和持续时间,均以纯文本格式呈现。在构建理解数据时,Emu3将部分数据中的 “caption text”字段移至[EOV] token之后。
训练目标:由于 Emu3 中的视觉信号已完全转换为离散token,因此只需使用标准的交叉熵损失进行下一个token预测任务的训练。为了防止视觉token在学习过程中占据主导地位,对与视觉token相关的损失加权 0.5。
训练细节:Emu3 模型在预训练期间利用非常长的上下文长度来处理视频数据。 为便于训练,采用了张量并行(TP)、上下文并行(CP)和数据并行(DP)相结合的方法。同时将文本和图像数据打包成最大上下文长度,以充分利用计算资源,同时需要确保在打包过程中不会分割完整的图像。
预训练过程分为两个阶段,第一阶段不使用视频数据,训练从零开始,文本和图像数据的上下文长度为 5,120;在第二阶段,引入视频数据,并使用 131,072 的上下文长度。
5 SFT阶段
5.1 视觉生成
质量微调:在预训练阶段之后,对视觉生成任务进行后训练,以提高生成输出的质量。使用高质量数据进行质量微调。
直接偏好优化:Emu3在自回归多模态生成任务中采用直接偏好优化(Direct Preference Optimization,DPO)技术,利用人类偏好数据来提高模型性能。
5.2 视觉语言理解
预训练模型经过两个阶段的视觉语言理解后训练过程:1) 图像到文本的训练以及 2) 指令调整。
第一阶段:将图像理解数据与纯语言数据整合在一起,而与视觉token相关的损失则在纯文本预测中被忽略。
第二阶段:利用 LLaVA 数据集中的约 320 万个问答对进行指令微调。低于 512 × 512 或高于 1024 × 1024 的图片将被调整到较低或较高的分辨率,同时保持相应的长宽比,而其他图片则保持原始分辨率。
开源地址
除了先前经SFT的Chat模型和生成模型外,智源研究院还在近日开源了Emu3生成和理解一体的预训练模型以及相应的SFT训练代码,以便后续研究和社区构建与集成。
代码:https://github.com/baaivision/Emu3
项目页面:https://emu.baai.ac.cn/
模型:https://huggingface.co/collections/BAAI/emu3-66f4e64f70850ff358a2e60f
未来方向
Emu3为多模态AI指出了一条富有想象力的方向,有机会将AI基础设施收敛到单一技术路线上,为大规模的多模态训练和推理提供基础。统一的多模态世界模型未来有广泛的潜在应用,包括自动驾驶、机器人大脑、智能眼镜助手、多模态对话和推理等。预测下一个token有可能通往AGI。
*本文系量子位获授权刊载,观点仅为作者所有。
— 完 —

量子位 QbitAI
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见 ~